
Someone asked on StackOverflow how to get loading a 1,000,000 records to be faster in SQL Developer.
My answer was basically, don’t use SQL Developer to load 1,000,000 records, use SQL*Loader.
Now, I also reminded folks that you can USE SQL Developer to build your SQL*Loader scenario. There’s 2 ways actually:
- Query existing records, export to Loader (Keep Reading this post!)
- Point to a CSV, and use the Import Data Wizard
But Wait, What is SQL*Loader? And Why? I Already Have SQL Developer!
SQL*Loader is the primary method for quickly populating Oracle tables with data from external files. It has a powerful data parsing engine that puts little limitation on the format of the data in the datafile. SQL*Loader is invoked when you specify the sqlldr command or use the Enterprise Manager interface.
SQL*Loader is an integral feature of Oracle databases and is available in all configurations.
And here are the Docs on how to use it.
Now you may think it’s weird to tell someone not to use SQL Developer. But it’s not – I’m helping our user find the best way using our tools to accomplish their goal – load 1,000,000 rows faster. And, they can still use SQL Developer to get started.
My ‘friend’ on StackOverflow didn’t seem to believe me that it was faster, so I was asked to PROVE IT. Here we go –
Creating the Table
CREATE TABLE "HR"."T_MILLION" ( "C1" NUMBER(*, 0), "C2" NUMBER(*, 0), "C3" NUMBER(*, 0), "C4" NUMBER(*, 0), "C5" NUMBER(*, 0), "C6" NUMBER(*, 0) ); -- now put a million rows in it BEGIN FOR i IN 1 .. 1000000 loop INSERT INTO t_million VALUES (1,2,3,4,5,6); END loop; commit; END; /
I ran this a couple of times. First run time was 22.842 seconds, and the second run was 29.858 seconds.
Oh, and let me describe my setup:
Windows 10, running VirtualBox Linux Image with 12cR2 db, using SQL Developer 18.3 on my Windows host, connecting to the db over a VBox networking port forward. And I was doing video conference AND installing Oracle 12cR2 client during my testing. So my machine was having LOTS of fun today.
Running INSERTs, row by row – in SQL Developer
I queried my table, used the SQL Developer EXPORT feature to export to an INSERT script, with no COMMITs.
And then I ran it.
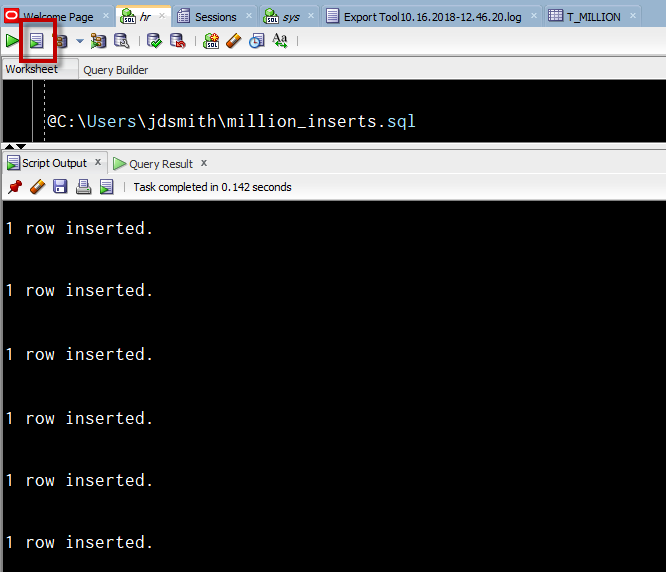
And I ran it for 17 minutes and 12 seconds before getting bored and cancelling the script. So that got me 353,233 records. Which tells me we were inserting about 342 records a second.
The SQL*Loader Solution
I truncated my table, and populated it again with my PL/SQL block above. Then I queried my table again and I created the SQL*Loader scenario:
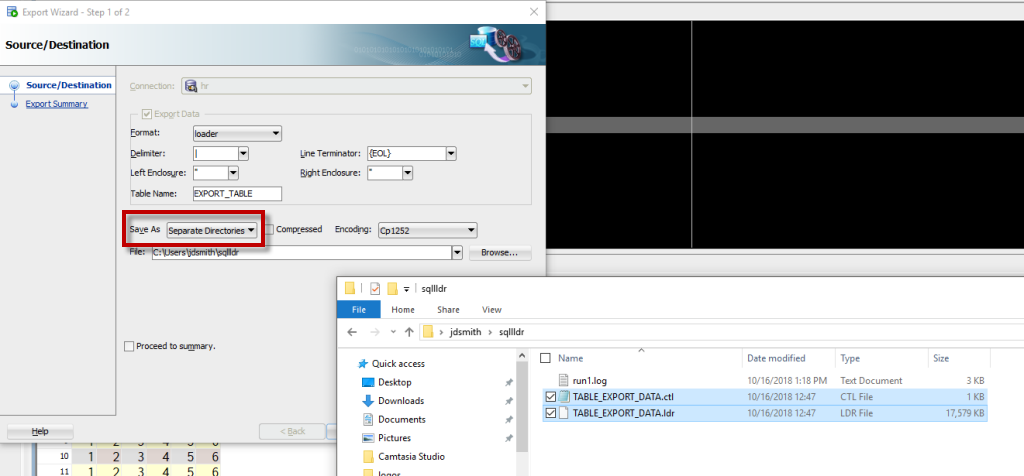
Note when doing this type of export, we write our 2 different files, so you MUST select a directory to write to.
I then downloaded and installed my 12cR2 Client. (Download for Windows 64 bit)
I did a ‘Custom’ install, put down Oracle NET and the developer tools (SQL*Plus and SQL*Loader). This took about…5 minutes.
I set my $ORACLE_HOME.
I opened a CMD window, navigated to my sqlldr directory where my CTL file was, and had at it:
sqlldr hr/oracle@localhost:1521/orcl CONTROL=TABLE_EXPORT_DATA.ctl LOG=run1.log BAD=records.bad
And the Results!
TABLE "T_MILLION": 1000000 ROWS successfully loaded. 0 ROWS NOT loaded due TO DATA errors. 0 ROWS NOT loaded because ALL WHEN clauses were failed. 0 ROWS NOT loaded because ALL FIELDS were NULL. SPACE allocated FOR bind array: 99072 bytes(64 ROWS) READ buffer bytes: 1048576 Total logical records skipped: 0 Total logical records READ: 1000000 Total logical records rejected: 0 Total logical records discarded: 0 Run began ON Tue Oct 16 13:17:07 2018 Run ended ON Tue Oct 16 13:18:40 2018 Elapsed TIME was: 00:01:33.01 CPU TIME was: 00:00:11.71
That, according to my math is 10,753 records inserted per second.
So, using SQL*Loader was 3,144% faster than SQL Developer.
Disclaimer: I suck at maths, so my numbers might be off, but the results are pretty clear.
Disclaimer: I did NO enhancements or tricks on either side – this was running everything at the defaults. I’m sure I could get the SQL*Loader scenario to run EVEN faster.
Connor Says: Hold My Beer

Connor from our AskTom team reminds me that there are faster ways to load this data. Specifically with these options:
OPTIONS (ERRORS=100000, BINDSIZE=8000000, ROWS=5000 )
And if you run this and BLINK, you’ll miss the magic:
SPACE allocated FOR bind array: 7740000 bytes(5000 ROWS) READ buffer bytes: 8000000 Total logical records skipped: 0 Total logical records READ: 1000000 Total logical records rejected: 0 Total logical records discarded: 0 Run began ON Wed Oct 17 10:13:10 2018 Run ended ON Wed Oct 17 10:13:18 2018 Elapsed TIME was: 00:00:08.49 CPU TIME was: 00:00:04.50
So we went from 1 minutes, 33 seconds to less than 9 seconds. That’s 111,111 rows per second. And this is on my crappy desktop machine connecting to a DB running in a very small Linux VM. So in real world, expect even better.
Nothing is free by they way, the read buffer goes way up…but I’ll write that check.




19 Comments
Hi Jeff,
I exported a table using the Export Loader Feature in SQLDeveloper. The table has among others these rows:
COLUMN_NAME DATA_TYPE NULLABLE
INSERT_DATE DATE Yes
TIME_STAMP TIMESTAMP(6) WITH TIME ZONE Yes
The Insert_Date gets exported with a correct format
CTL File: “INSERT_DATE” DATE “YYYY-MM-DD HH24:MI:SS” ,
LDR File: 2021-11-15 15:04:17
but the TIME_STAMP Row does not match:
CTL File: “TIME_STAMP” TIMESTAMP WITH TIME ZONE “YYYY-MM-DD HH24:MI:SS.FF TZH:TZM” )
LDR File: 15.11.21 15:04:17,375812000 +01:00
Due to the Missmatch I get these errors during the import.
Record 10: Rejected – Error on table “TRANSFER_QUEUE_BAK”, column “TIME_STAMP”.
ORA-01874: time zone hour must be between -15 and 15
Record 11: Rejected – Error on table “TRANSFER_QUEUE_BAK”, column “TIME_STAMP”.
ORA-01830: date format picture ends before converting entire input string
Is this a bug in SQL Developer? I´m using Version 21.2.1.204
Best regards
Jens
Sounds like it, I would open a SR with MOS and provide a reproducible scenario.
Easy fix would be to update the ctl file to have the format match what’sin the ldr file?
Hi Jeff, thanks for this post. I indeed like sqlldr for bulk load however my question is how can we generate CTL file for every table in Db? I want to migrate Sybase into Oracle 12c but unforunately have to use manual scripts instead of migration user. any suggestions?
Our migration feature will do this for you. See this.
hi,
when:
1.under windows
2.seperate directories & compressed mode,
the ctl & ldr files contain windows format path seperator: \
can’t generate unix format: /
this is a bug ?
Have you tried running SQLDev on a linux desktop instead?
I not have linux desktop, only run sqldeveloper in windows,
I want to prepare ctl & ldr files, will run in linux with terminal.
Then you need to use a text editor and search and replace to fix the file after SQL Developer built it. Or run SQL Developer in Linux to prepare the scenario.
Oracle sQl Developer
That’s the name – did you have a question?
How did the number 5000 get chosen for the number of rows? It appears that 8000000 was chosen because of the number of bytes in 5000 rows. Is that right?
If our tables are wider, should we chose fewer rows? How can we know what number is best for our table?
Pretty much, if you look at the docs –
A bind array is an area in memory where SQL*Loader stores data that is to be loaded. When the bind array is full, the data is transmitted to the database. The bind array size is controlled by the BINDSIZE and READSIZE parameters.
The size of the bind array given by BINDSIZE overrides the default size (which is system dependent) and any size determined by ROWS.
So fewer back and forths from client to server…sounds like a great question for AskTom.
It better be! That’s it job after all. 🙂
OK I am probably being stupid and realize this question is slightly off the point of your post but why is the insert in the PL/SQL block only taking 22 seconds and the script with individual inserts but *no commit* taking so much longer?
The main thing that masks the PL/SQL block so much faster is that it’s doing a bulk insert. PL/SQL does this “automagicly” and converts the single row inserts in to a bulk operation, which in effect inserts 100s of rows at a time. The insert script that SQL Developer is running is running each insert as a single command. This is a classic “Row by slow” operation. But PL/SQL is slow compared to SQL Loader and as Jeff says, this could be even faster. Using direct path would likely cut the time by a significant amount. Hope this helps – Ric
Thanks for the assist, Ric!
Thanks for the explanation Ric and for managing to use the word “automagicly” along the way 🙂
Of course if your file is on the server, you can just use external tables and not worry just because your local sqlldr.exe is broken. 🙂
Unfortunately, a lot of Data Engineers and Data Scientists (say, in an Analytics shop) do not have access to a folder residing on the DB Server and DBAs may not be inclined to give access due to “security” concerns. Hence, having a handy utility to load records super fast is awesome!