

SQL Developer Web has over the last 6 months been aggressively adding and enhancing support for working with the JSON in your Oracle Database. Catch up here.
I wanted to talk to you today about:
- how to sort your JSON Docs
- how to do text searches for any attribute in your JSON Docs
In SQL, ordering your results is as simple as using the ORDER BY clause, a la –
SELECT * FROM TWEETS
ORDER BY TWEET_ID ASC
The database KNOWS that TWEET_ID is column in my TWEETS table, and is defined as a NUMBER. But, in the JSON Document Store world since the JSON Document defines the schema, you may need to give the database some help when it comes to sorting.
Let’s take a quick look!
JSON ORDER BY’s
I want to see my tweets, ordered by the number of times someone clicked the ‘Favorite’ button.
About a year ago, I downloaded my Twitter personal data, 100,000+ tweets. It comes in a big archive ZIP of JSON files. I used THIS method to upload them, in a single POST to my Always Free Autonomous Database (ATP).
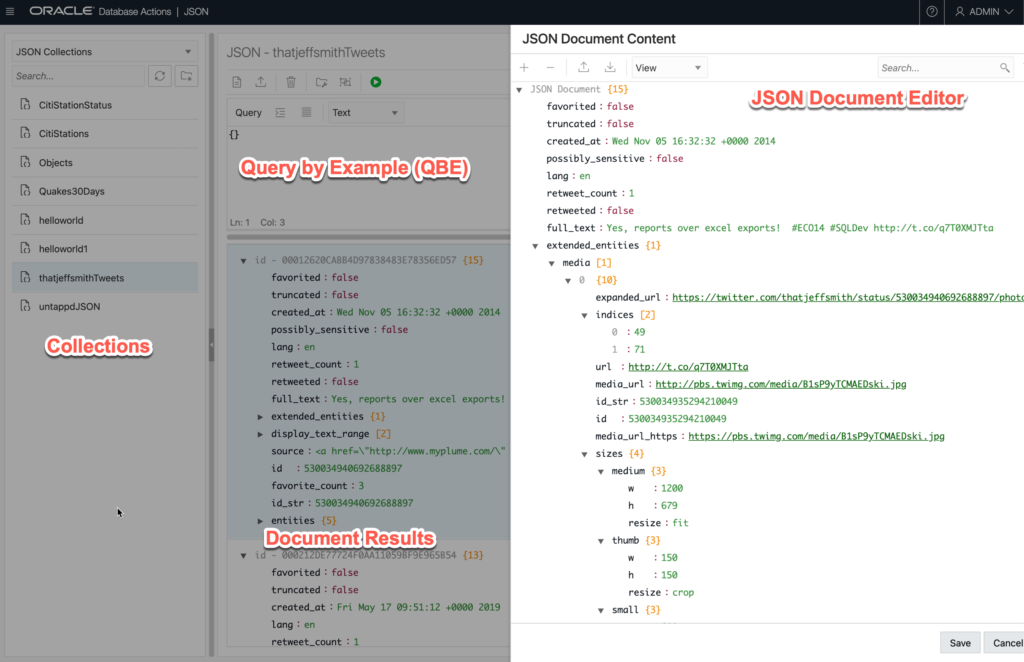
If we look at one of those documents –
{
"favorited": false,
"truncated": false,
"created_at": "Wed Nov 05 16:32:32 +0000 2014",
"possibly_sensitive": false,
"lang": "en",
"retweet_count": "1",
"retweeted": false,
"full_text": "Yes, reports over excel exports! #ECO14 #SQLDev http://t.co/q7T0XMJTta",
"extended_entities": {
"media": [
{
"expanded_url": "https://twitter.com/thatjeffsmith/status/530034940692688897/photo/1",
"indices": [
"49",
"71"
],
"url": "http://t.co/q7T0XMJTta",
"media_url": "http://pbs.twimg.com/media/B1sP9yTCMAEDski.jpg",
"id_str": "530034935294210049",
"id": "530034935294210049",
"media_url_https": "https://pbs.twimg.com/media/B1sP9yTCMAEDski.jpg",
"sizes": {
"medium": {
"w": "1200",
"h": "679",
"resize": "fit"
},
"thumb": {
"w": "150",
"h": "150",
"resize": "crop"
},
"small": {
"w": "680",
"h": "385",
"resize": "fit"
},
"large": {
"w": "1344",
"h": "760",
"resize": "fit"
}
},
"type": "photo",
"display_url": "pic.twitter.com/q7T0XMJTta"
}
]
},
"display_text_range": [
"0",
"71"
],
"source": "<a href="\"http://www.myplume.com/\"" rel="\"nofollow\"">Plume for Android</a>",
"id": "530034940692688897",
"favorite_count": "3",
"id_str": "530034940692688897",
"entities": {
"user_mentions": [],
"urls": [],
"symbols": [],
"media": [
{
"expanded_url": "https://twitter.com/thatjeffsmith/status/530034940692688897/photo/1",
"indices": [
"49",
"71"
],
"url": "http://t.co/q7T0XMJTta",
"media_url": "http://pbs.twimg.com/media/B1sP9yTCMAEDski.jpg",
"id_str": "530034935294210049",
"id": "530034935294210049",
"media_url_https": "https://pbs.twimg.com/media/B1sP9yTCMAEDski.jpg",
"sizes": {
"medium": {
"w": "1200",
"h": "679",
"resize": "fit"
},
"thumb": {
"w": "150",
"h": "150",
"resize": "crop"
},
"small": {
"w": "680",
"h": "385",
"resize": "fit"
},
"large": {
"w": "1344",
"h": "760",
"resize": "fit"
}
},
"type": "photo",
"display_url": "pic.twitter.com/q7T0XMJTta"
}
],
"hashtags": [
{
"text": "ECO14",
"indices": [
"34",
"40"
]
},
{
"text": "SQLDev",
"indices": [
"41",
"48"
]
}
]
}
}We can see the way Twitter stores a Tweet has a pretty interesting ‘schema’ – and it gives me a lot of fun queries I can run.
Let’s look at a couple of attributes as examples –
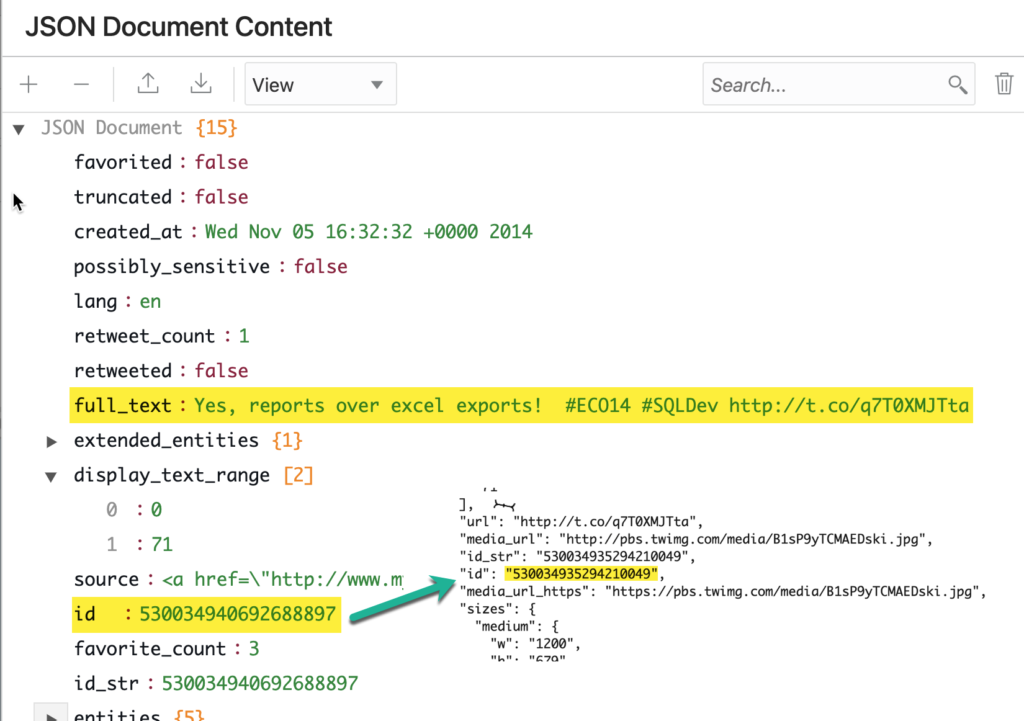
So I have the ‘meat’ of the Tweet, stored as “full_text”, and then I have some other interesting attributes like the Tweet ID and even, how many times it’s been retweeted or favorited.
Simple {abbreviated} Order By Syntax
I can very simply say I want the results ordered by “favorite_count”, DESC. It’s fun for my EGO to sort the Tweets in order of their popularity – and also it’s easy to see the discrepancy of doing a sort by number vs by text.
In the editor, use this text to define a ORDER BY
{
"favorite_count": -1
}
It’s a JSON document, with the attributes followed by a 1 or -1. 1 is a normal/default sort of ASC, and -1 is a DESC.
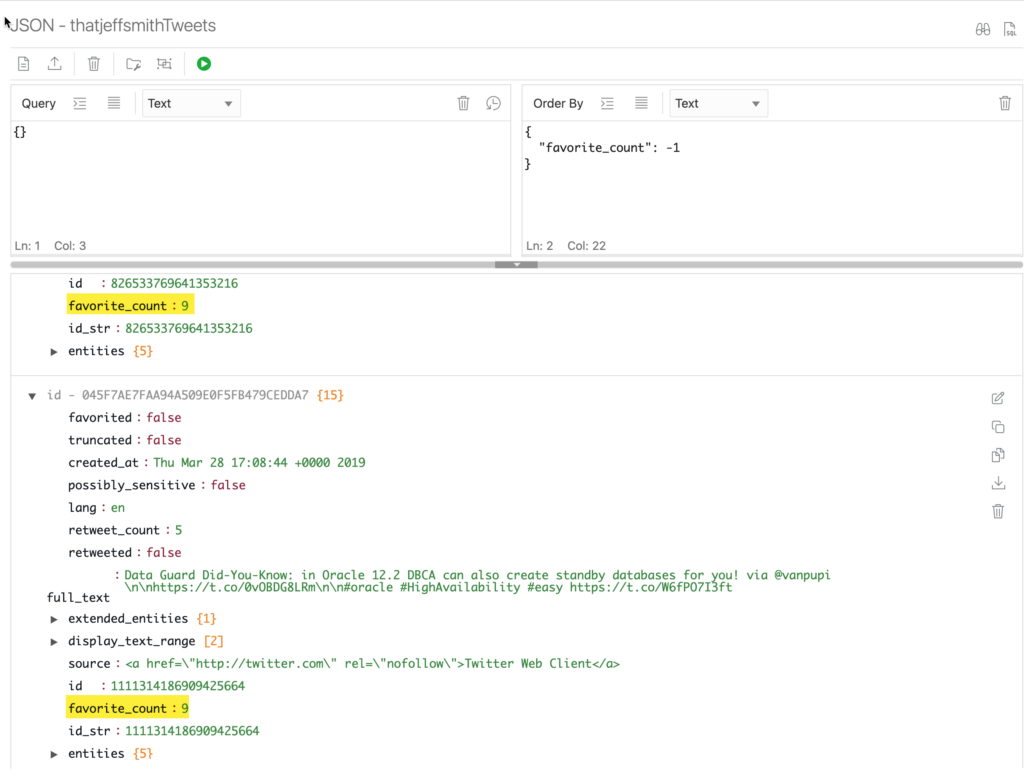
This seems FISHY to me! I know my data, so I know enough to know that’s not ‘right’ – or, perhaps I’m not asking in the correct fashion. This is a case where the SODA APIs have to construct SQL for the database, and at the time of the call, there’s not enough KNOWN about the documents to give the database a heads-up that it’s about to be working with NUMBERs.
Thankfully, there’s a solution!
Advanced {array} Order By Syntax
So instead of relying on the optimizer to ‘guess’ or infer what the TYPE, we can simply tell it, at the time we issue the query.
[
{
"path": "favorite_count",
"datatype": "number",
"order": "desc"
}
]
Running the query again, the results are QUITE different.
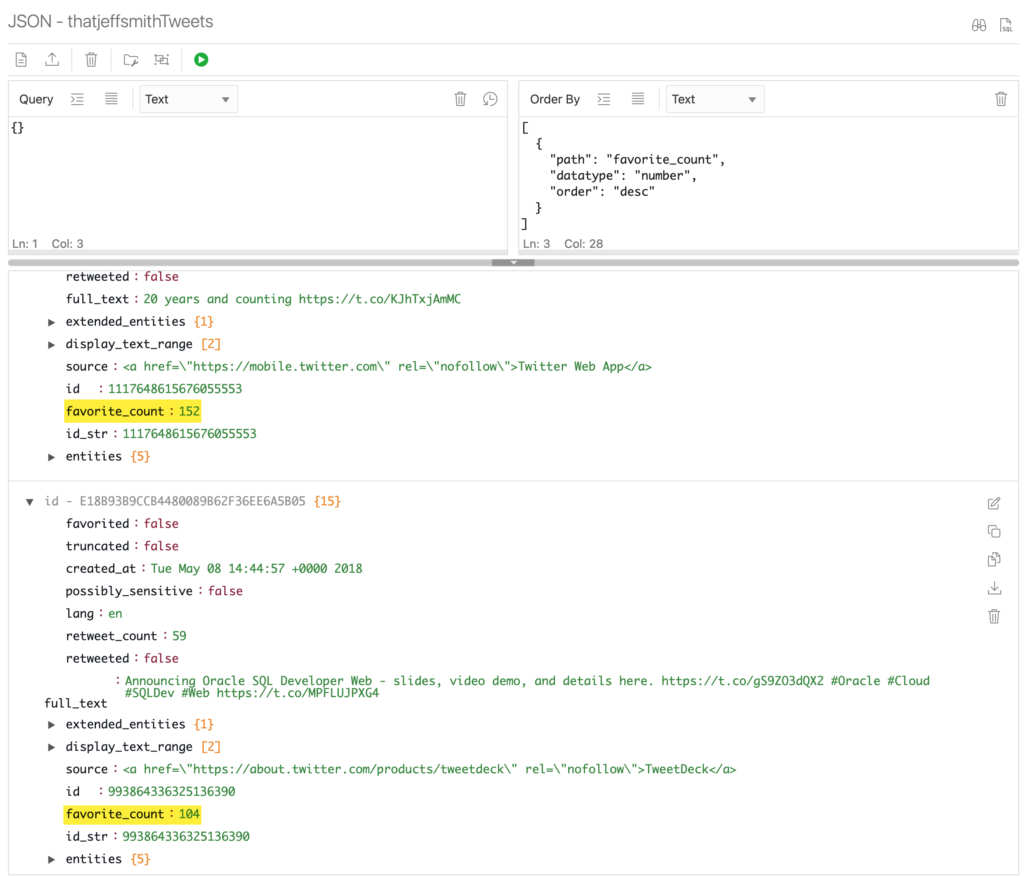
So what happens behind the scenes?
If we make our call manually, I can ask the SODA for REST API to include the SQL that was used to satisfy the request. So we can go from SODA to SQL!
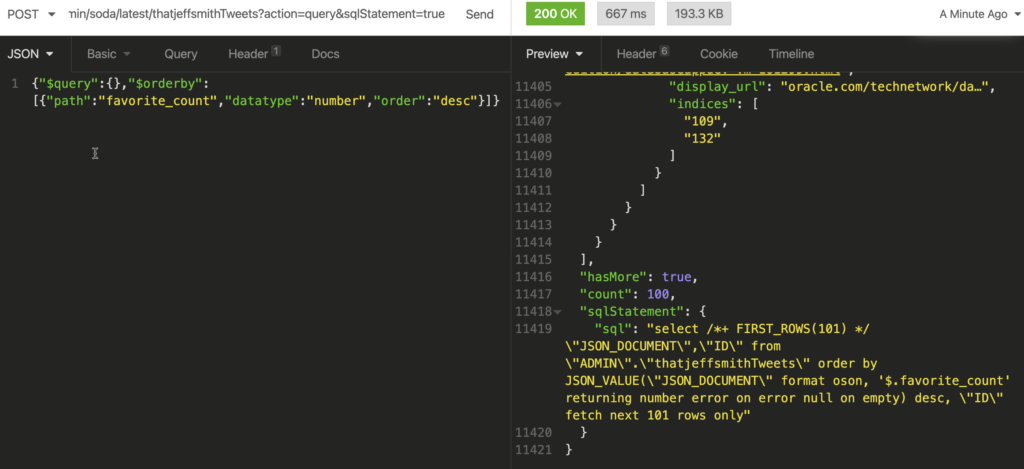
The magic SQL, is:
SELECT /*+ FIRST_ROWS(101) */ "JSON_DOCUMENT" , "ID" FROM "ADMIN"."thatjeffsmithTweets" ORDER BY JSON_VALUE ( "JSON_DOCUMENT" format oson, '$.favorite_count' returning NUMBER error ON ERROR NULL ON empty ) DESC, "ID" fetch NEXT 101 ROWS ONLY
The most important keywords here are ‘returning number’.
SELECT * FROM is B-O-R-I-N-G!
My QBE strings in these examples have all been ‘{}’ – which will MATCH ALL documents in my collection.
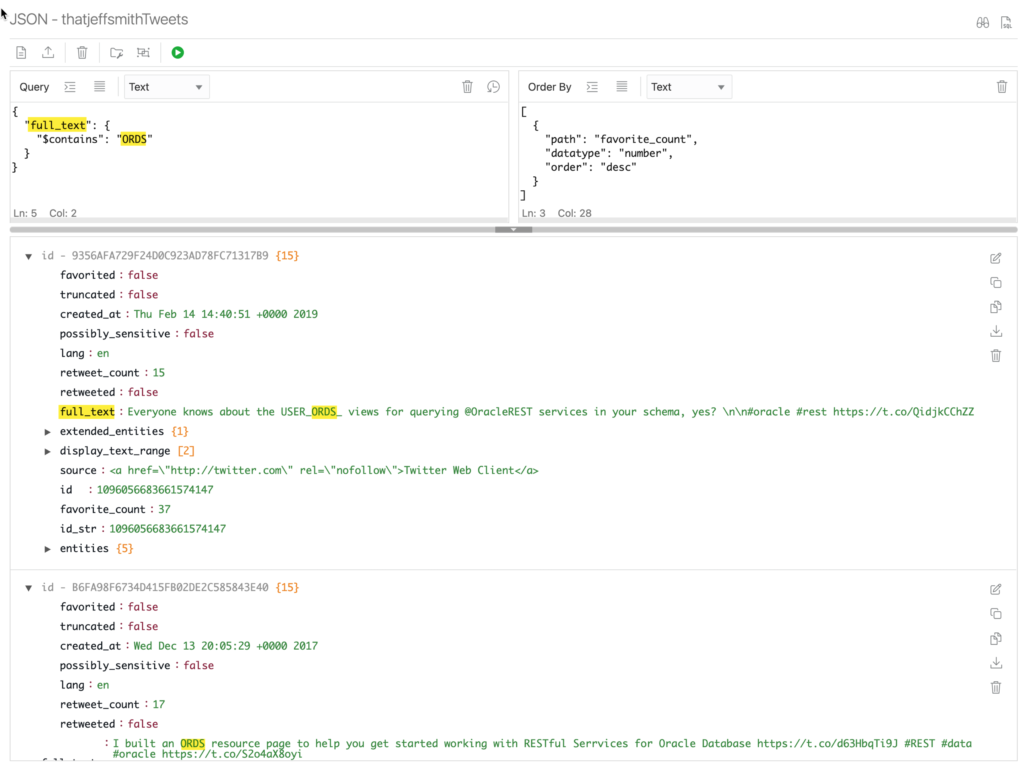
What if…I wanted to know what tweets were favorited most where I mentioned ORDS?
All I need to do is first create a JSON SEARCH INDEX (text), and then I can run some very simple (yet powerful) queries across my collection documents.
I’ve already created the INDEX, now onto the QBE. For the “full_text” attribute use the contains function.
So let’s do the search, but let’s look for any mention of the words “ORDS” in the text field for my tweets..and let’s order them in descending order of the number of times they’ve been favorited. Added bonus, these aren’t case-sensitive!
{
"full_text": {
"$contains": "ORDS"
}
}
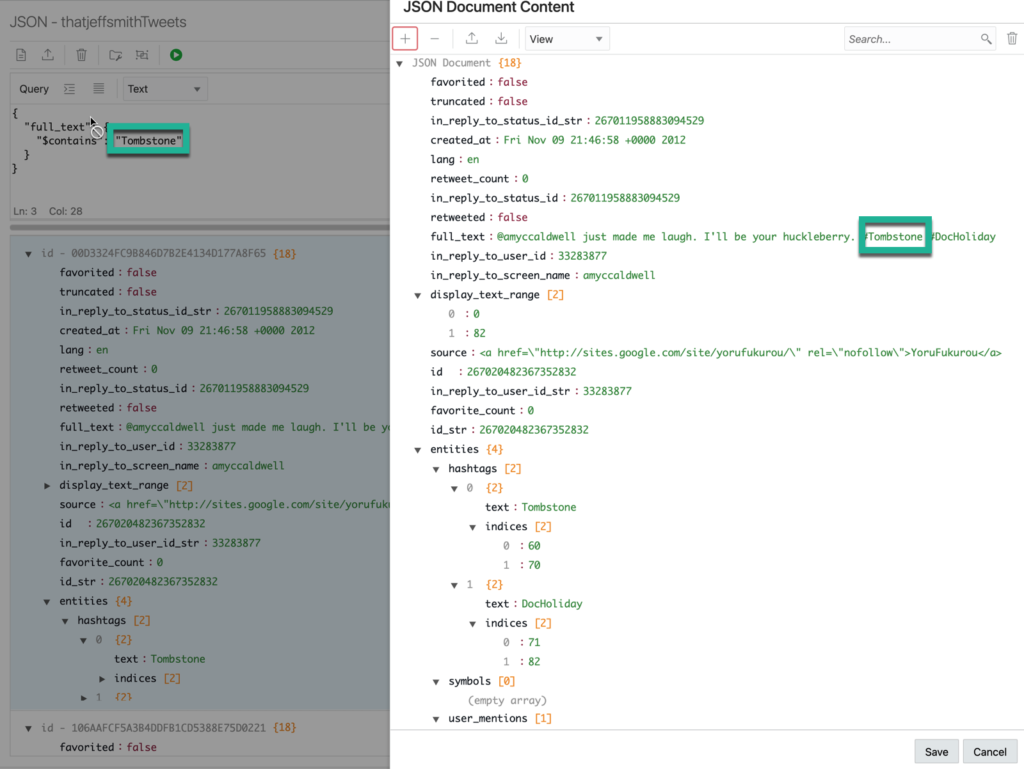
I tweet about all kinds of things, so I can look for where I tweeted about my favorite movies or beer or…
Resources / Documentation Links
There’s a lot of technology bits included in this blog post, here’s a list of everything covered:




