
I have 1,500 rows I need to shove into a table. I don’t have access to the database, directly.
But my DBA is happy to give me a HTTPS entry point to my data.
What do I do?
Let’s look at a Low-Code solution:
Oracle REST Data Services & Auto REST for tables.
With this feature, you can say for a table, make a REST API available for:
- querying the table
- inserting a row
- updating a row
- deleting a row
- getting the metadata for a table (DESC)
- bulk load the table
Now I’ve previously shown how to INSERT a record to a table with ORDS via POST.
But that’s just one row at a time.
Let’s do it for 1500 rows. And I don’t have the data in JSON. No, my data nerd has given me a CSV ‘dump.’
How do I get it in?
If you want to consult the ORDS Docs, this is what we’re going to be using (DOCS).
For the POST to be received happily by ORDS, we ASSUME:
- the URI is avail, as the table has been REST enabled
- the first rows will be the column names
- the rest of the rows are your data
You have lots of options you can pass as parameters on the call. See the DOCS link above.
Ok, let’s do it.
Build Your Table
I’m going to run this code in SQL Developer.
CREATE TABLE stuff AS SELECT OWNER, object_name, object_id, object_type FROM all_objects WHERE 1=2; CLEAR SCREEN SELECT /*csv*/ OWNER, object_name, object_id, object_type FROM all_objects fetch FIRST 1500 ROWS ONLY;
That spits out a new table:
…and some CSV that looks like this:
"OWNER","OBJECT_NAME","OBJECT_ID","OBJECT_TYPE" "SYS","I_FILE#_BLOCK#",9,"INDEX" "SYS","I_OBJ3",38,"INDEX" "SYS","I_TS1",45,"INDEX" "SYS","I_CON1",51,"INDEX" "SYS","IND$",19,"TABLE" "SYS","CDEF$",31,"TABLE" "SYS","C_TS#",6,"CLUSTER" "SYS","I_CCOL2",58,"INDEX" "SYS","I_PROXY_DATA$",24,"INDEX" "SYS","I_CDEF4",56,"INDEX" "SYS","I_TAB1",33,"INDEX" "SYS","CLU$",5,"TABLE" "SYS","I_PROXY_ROLE_DATA$_1",26,"INDEX" ...
REST Enable the Table
You’ve already got ORDS going. You’ve already got your schema REST enabled, now you just need to do this bit to get your GET, POST, PUT, & DELETE HTTPS methods available for the Auto Table bits.
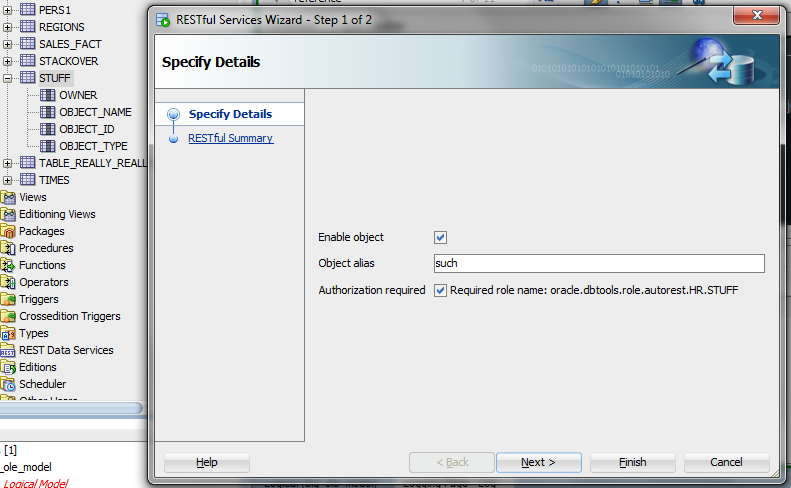
Now we can make the call.
We POST to the endpoint, it’s going to follow this structure:
/ords/schema/table/batchload
The CSV will go in the POST body.
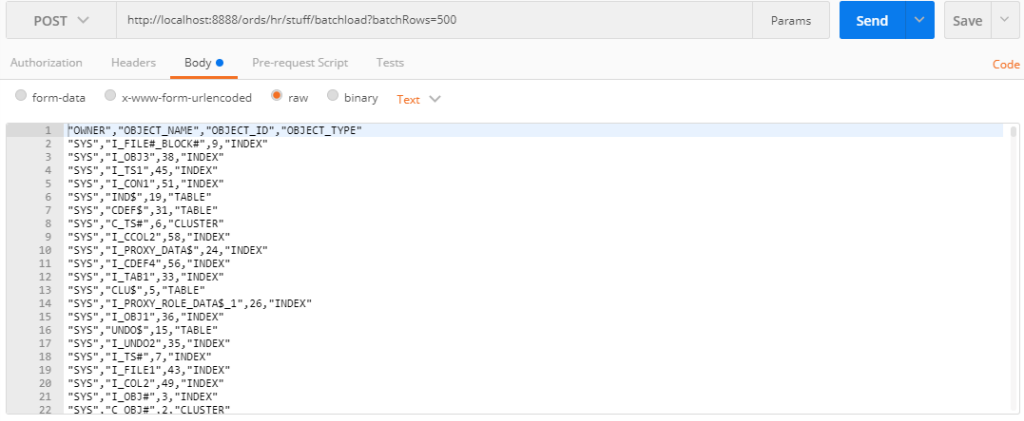
The CURL would look like this:
curl -X POST \ 'http://localhost:8888/ords/hr/stuff/batchload?batchRows=500' \ -H 'cache-control: no-cache' \ -H 'postman-token: 1eb3f365-f83d-c423-176d-7e8cd08c3eab' \ -d '"OWNER","OBJECT_NAME","OBJECT_ID","OBJECT_TYPE" "SYS","I_FILE#_BLOCK#",9,"INDEX" "SYS","I_OBJ3",38,"INDEX" "SYS","I_TS1",45,"INDEX" "SYS","I_CON1",51,"INDEX" "SYS","IND$",19,"TABLE" "SYS","CDEF$",31,"TABLE" "SYS","C_TS#",6,"CLUSTER" "SYS","I_CCOL2",58,"INDEX" "SYS","I_PROXY_DATA$",24,"INDEX" "SYS","I_CDEF4",56,"INDEX" "SYS","I_TAB1",33,"INDEX" "SYS","CLU$",5,"TABLE" "SYS","I_PROXY_ROLE_DATA$_1",26,"INDEX" ...
And the results…about 6 seconds later.

And just because I like to double check…
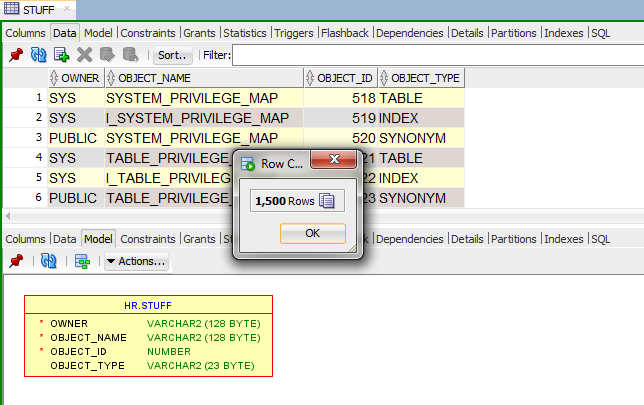
The first time I tried this, it was with ?batchRows=100, so 15 COMMITs for the load, and it took 12 seconds. So I cut the time in half by doing baches of 500 rows at a time. You’ll want to experiment for yourself to find an acceptable outcome.
Trivia, caveats, etc.
The ORDS code that takes the CSV in and INSERTs it to the table is the SAME code SQL Developer uses here:
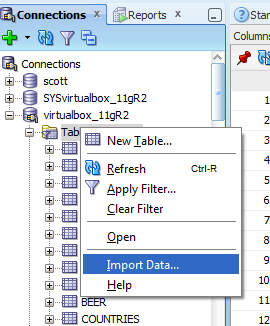
And it’s the same code SQLcl users here:
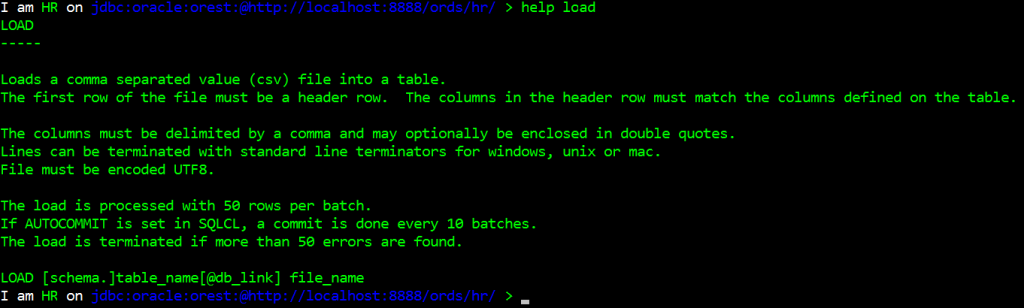
This is not the ideal way to load a LOT of data.
ORDS performs BATCH INSERTS (not 1 by 1!) to add your data using the AUTO route. An external table and CTAS will almost always be faster. And of course you have SQL*Loader and DataPump. But those require database access. This does NOT.
Or, you could always roll your own code and build your own RESTful Service. And perhaps you should. But if quick and dirty are good enough for you, we won’t tell anyone.

 for your Oracle REST APIs")
 with SQLcl")
8 Comments
Hi Jeff!
I wonder how I can get the column headings to show up in an csv output?
I’m using source type Query, Data format CSV, pagination size 25. But the output is NOT showin the column headings??
Regards
/Ulf
For ORDS, you can’t.
Unless you want to generate the output yourself…
Hi Jeff,
Thank you very much for your tuto. I managed to make it work without any problems.
However I am facing problem with accents. Is there a way to force charset to windows-1252?
Thank you
I’ve run this as mentioned in an Oracle tutorial, and it runs without problems.
https://docs.oracle.com/database/ords-18.1/AELIG/developing-REST-applications.htm#GUID-CA242E61-9012-4081-85A0-CC410B18A3CD
Example:
POST http://localhost:8080/ords/ordstest/emp/batchload?batchRows=25
Content-Type: text/csv
empno,ename,job,mgr,hiredate,sal,comm,deptno
0,M,SPY MAST,,2005-05-01 11:00:01,4000,,11
7,J.BOND,SPY,0,2005-05-01 11:00:01,2000,,11
9,R.Cooper,SOFTWARE,0,2005-05-01 11:00:01,10000,,11
26,Max,DENTIST,0,2005-05-01 11:00:01,5000,,11
However, if I move the data into a file named postbatch.dat (and give the rows new empno values) and call:
PATHTOFILE=`pwd`/postbatch.dat
echo $PATHTOFILE
curl -i -X POST “http://localhost:8080/ords/ordstest/emp/batchload?batchRows=25” \
-H “Content-Type: text/csv” \
-d @${PATHTOFILE}
Where postbatch.dat looks like:
empno,ename,job,mgr,hiredate,sal,comm,deptno
421,AdamBatFile,SOFTWARE,0,2005-05-01 11:00:01,10000,,11
423,BennyBatFile,SPY MAST,,2005-05-01 11:00:01,4000,,11
425,CarlBatFile,DENTIST,0,2005-05-01 11:00:01,5000,,11
427,DavidBatFile,SPY,0,2005-05-01 11:00:01,2000,,11
I get this output:
HTTP/1.1 200
Content-Type: text/plain
Transfer-Encoding: chunked
Date: Thu, 13 Sep 2018 13:29:49 GMT
#ERROR Column in header row deptno421 is not defined for table.
#INFO Number of rows processed: 0
#INFO Number of rows in error: 0
3 – SEVERE: Severe error, processing terminated
The way I figure, loader cannot see new lines.
It’s all done on a Oracle Linux 6.6
I check the encoding:
echo $LANG
en_US.UTF-8
I check the file’s mime-type:
file –mime-type ./postbatch.dat | awk ‘{print $2}’
text/plain
Could the actual mime-type be a problem?
Any suggestions?
Hi Jeff, is this the only way to do a batch load? I’m looking for an “application/json” batch load.
Regards,
Sebastián
The only way to do batch load out of the box, yes. You could do it, but would need to write a stored proc and probably use the newer 12.2 JSON parser/packages out there to transform it to rows to be inserted into a table. If I have time/resources, I’ll look into an example of what that might look like.
That would be awesome, thanks 🙂
Regards,
Sebastián
Hi Jeff,
Tried the above and it was an easy way to import ~1500 records into a table. I have a requirement that asks to create an extract (approx 200k records) to be generated and saved to a file for processing by an external system. My question here is – Is it a good practice to use ORDS API on the procedure to generate this extract, so the external system can invoke it? Or basically when to use ORDS APIs and when not to?