Subscribers and my mom will probably remember that I’ve briefly talked about this feature before, but it was really just a tease. I wanted to go into a bit more detail today.
In version 21.3, SQLcl got a wicked cool new feature. And yes, it sounds pandering of me to say that, but every now and then I see new features come out that turn out to be JUST as handy as we imagined them when we set out to build them.
This is one of those feature I’ll probably toss out in every Tips & Tricks talk I do going forward.
You have: a delimited text file or simply a CSV.
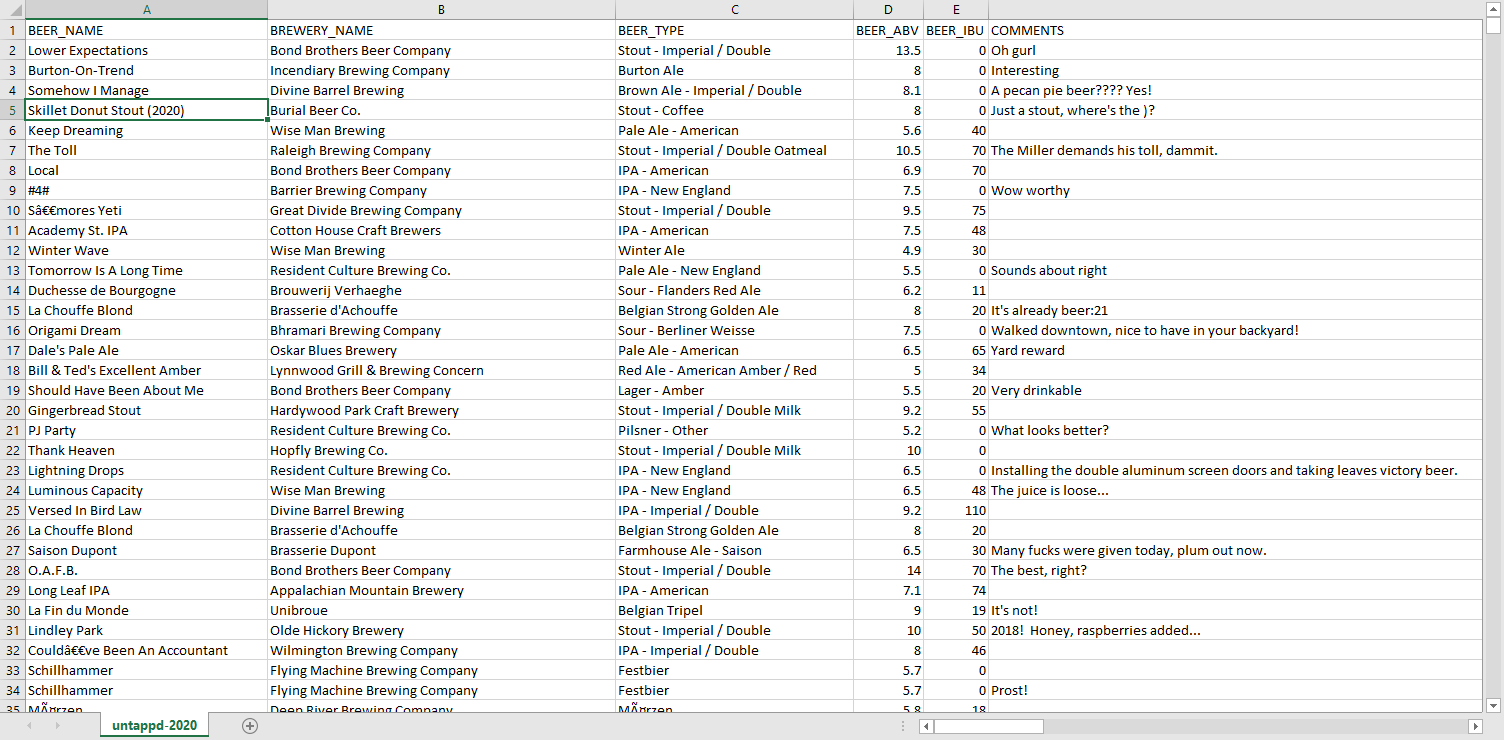
Putting that data into a table.
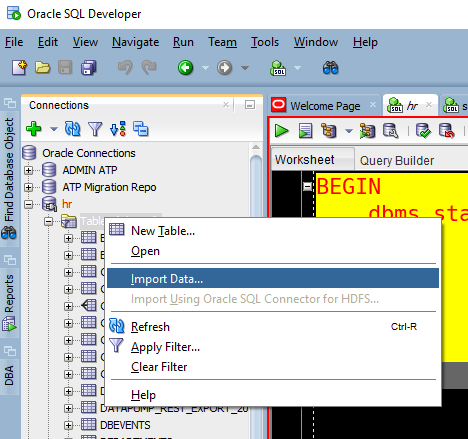
But, it’s a wizard, has multiple steps, and I don’t have SQLDev started, and I’m already at my prompt, ready to go, NOW.
The New-School Way
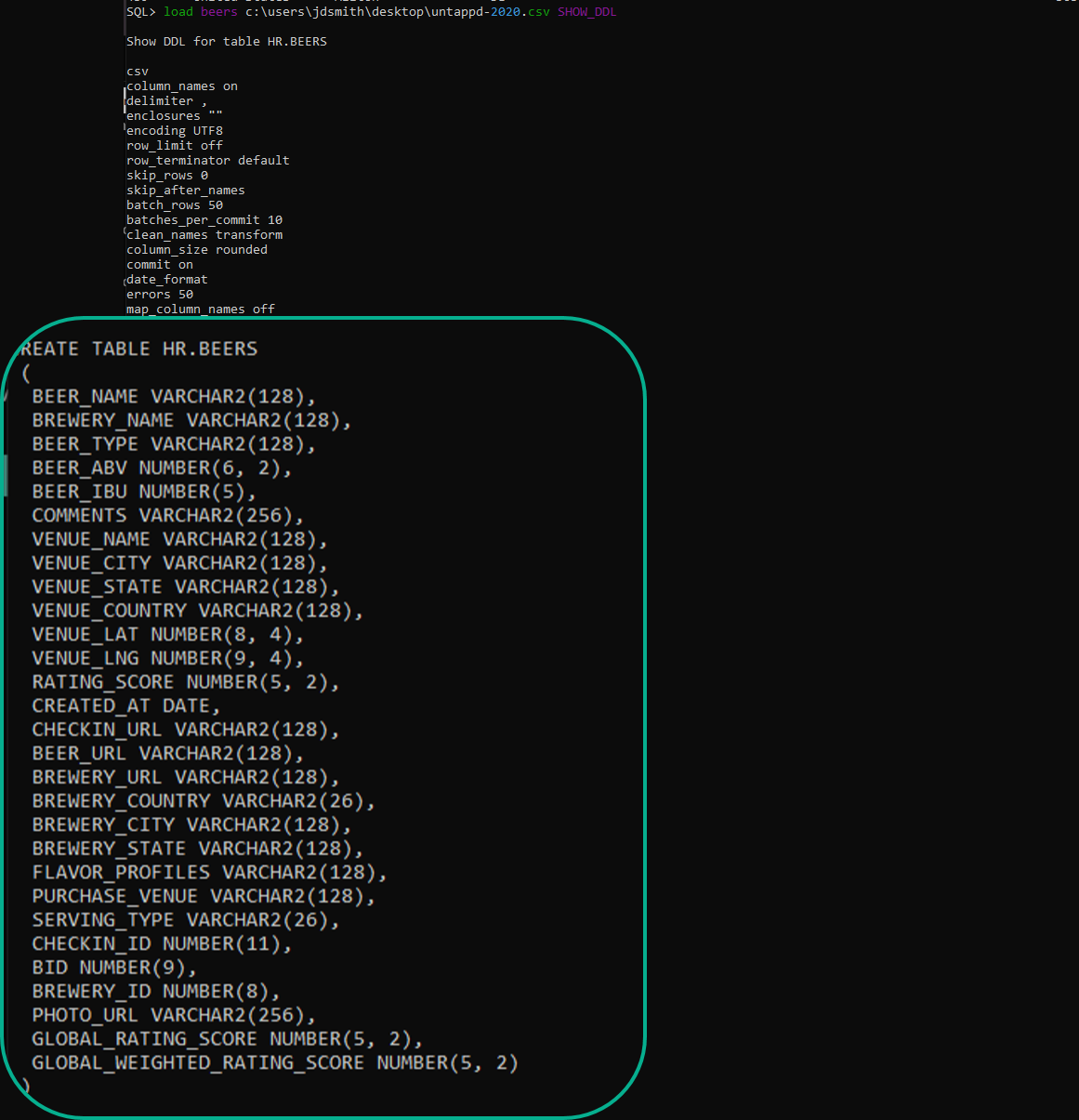
The LOAD command has a new parameter you can toss onto a job, ‘NEW’.
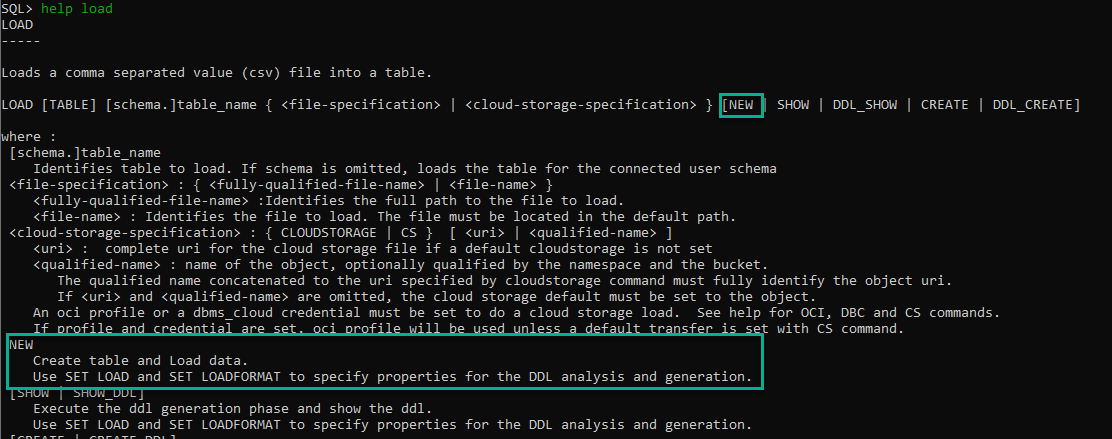
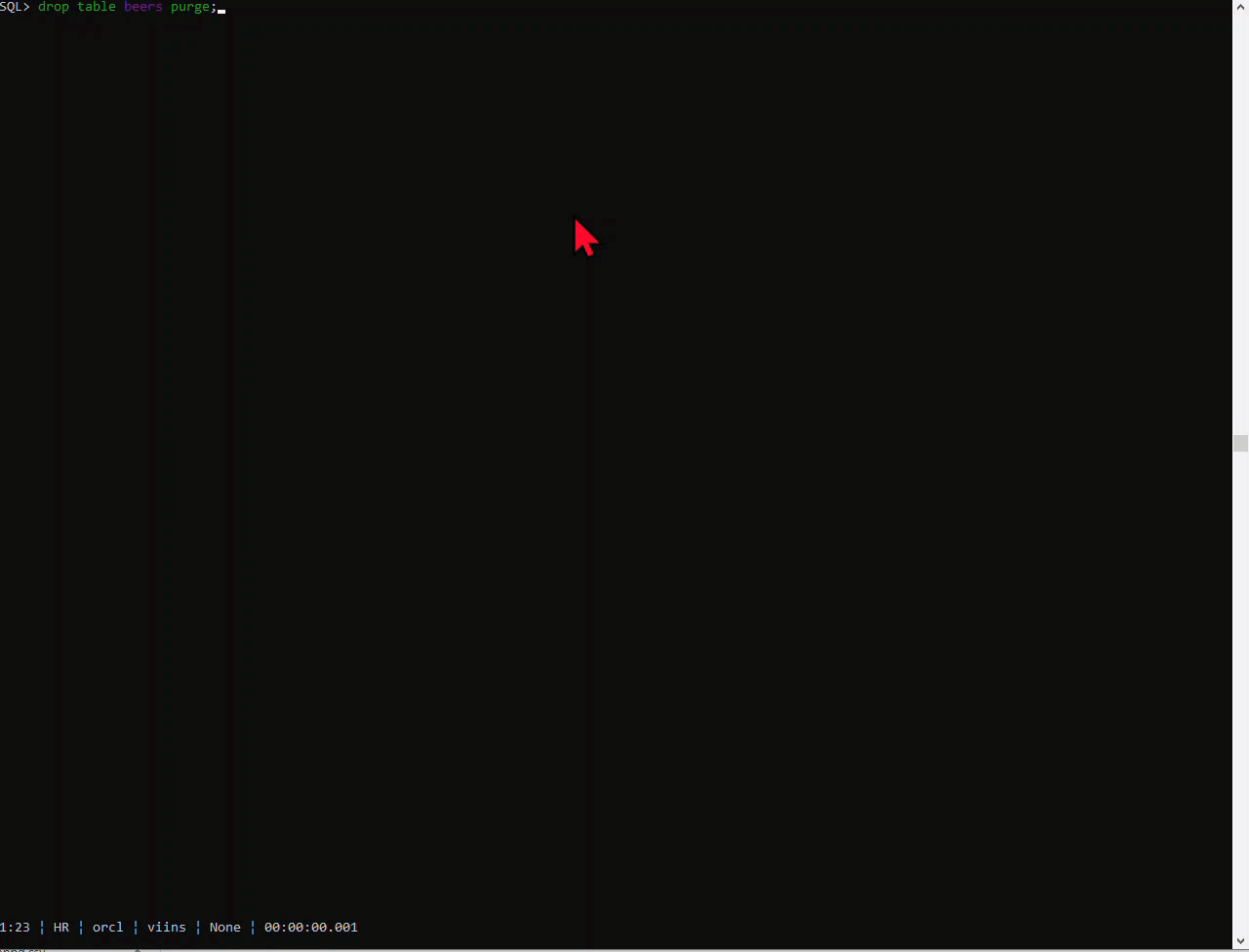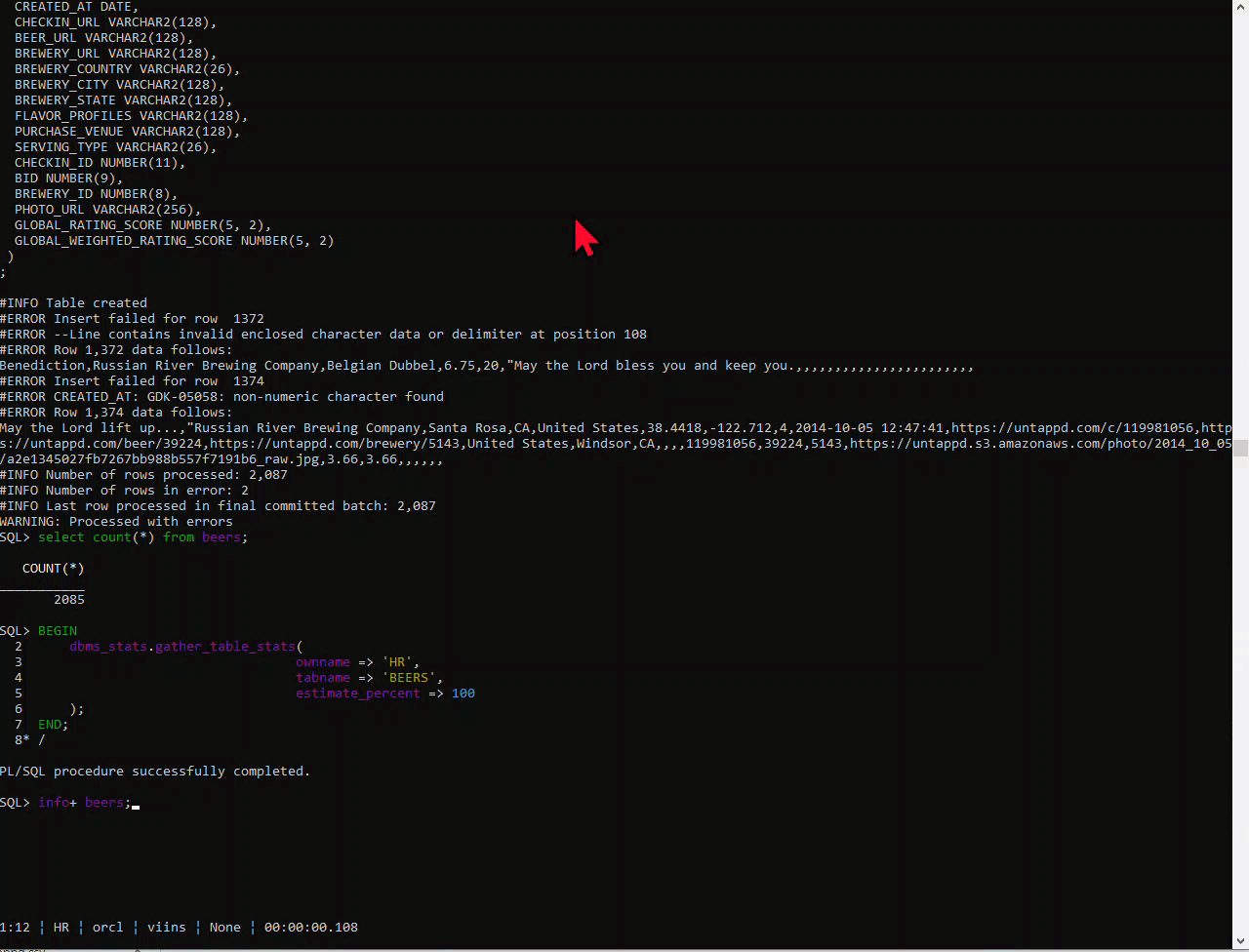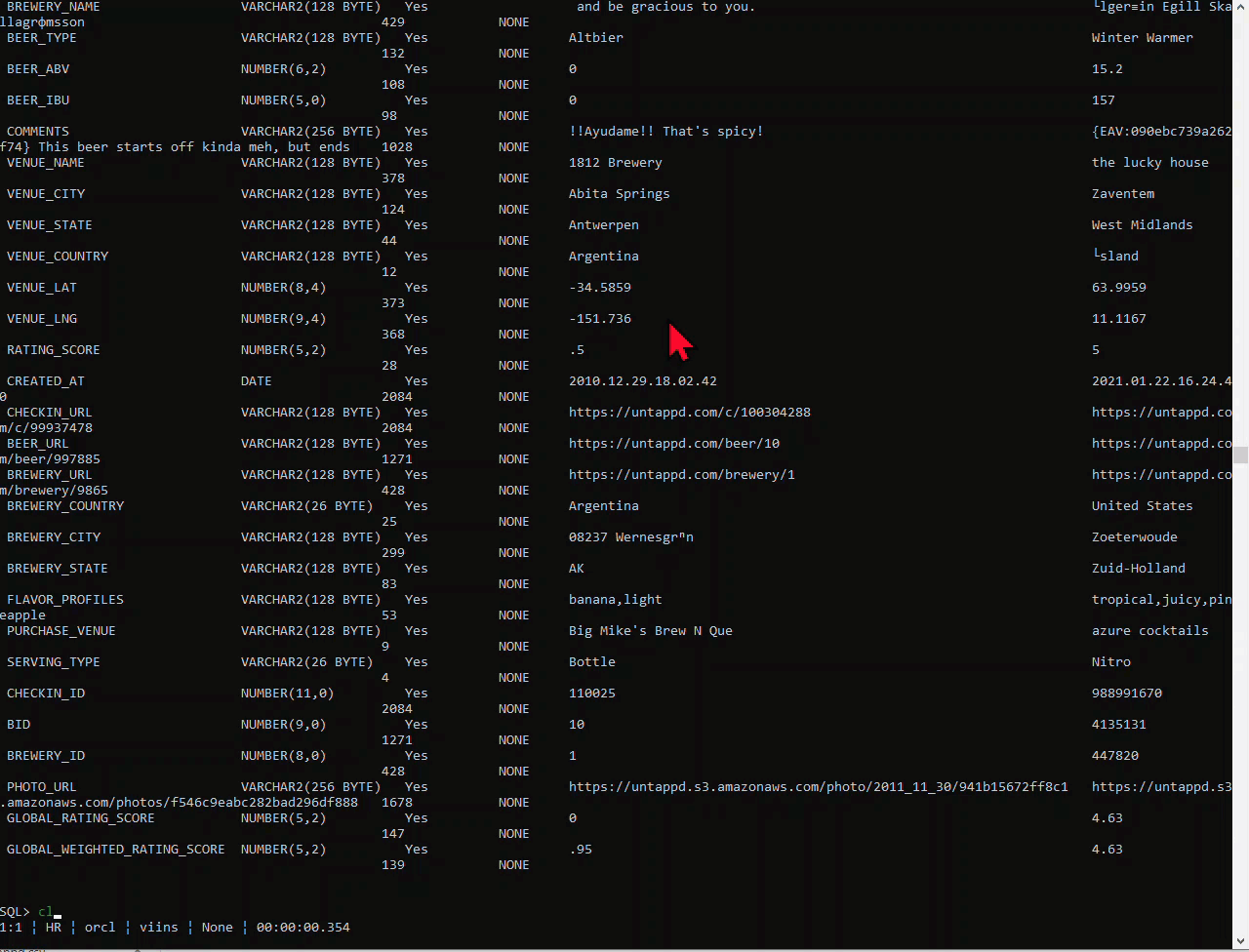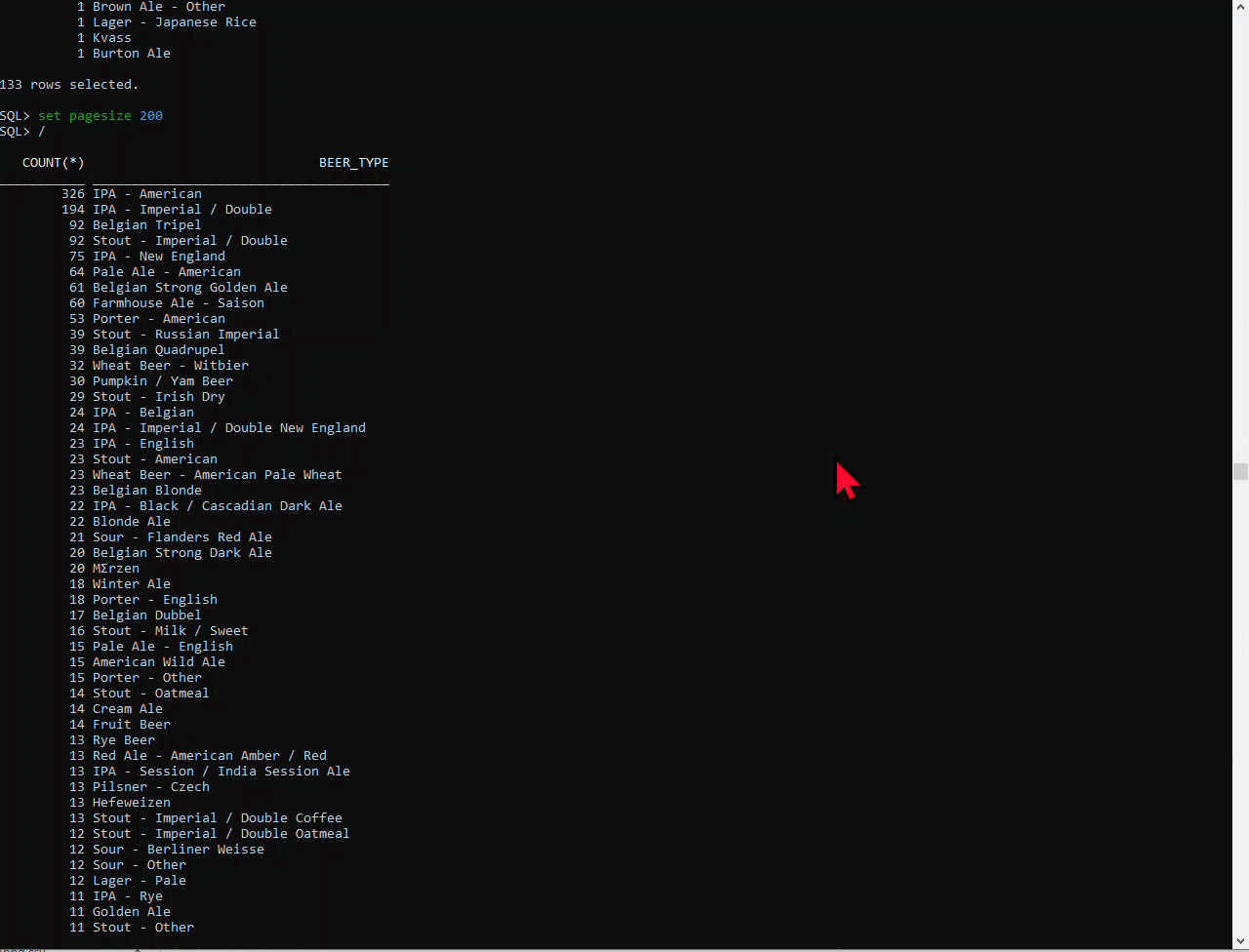
So what does this command do? Well, we scan your data from the CSV, we look at the column headers to come up with new column names, and then we look at the data itself – how wide are the strings, is that a DATE format we recognize, etc.
Then we show you that DDL, execute it, and then load the data from the CSV into the new table.
Which looks a LITTLE something like this –
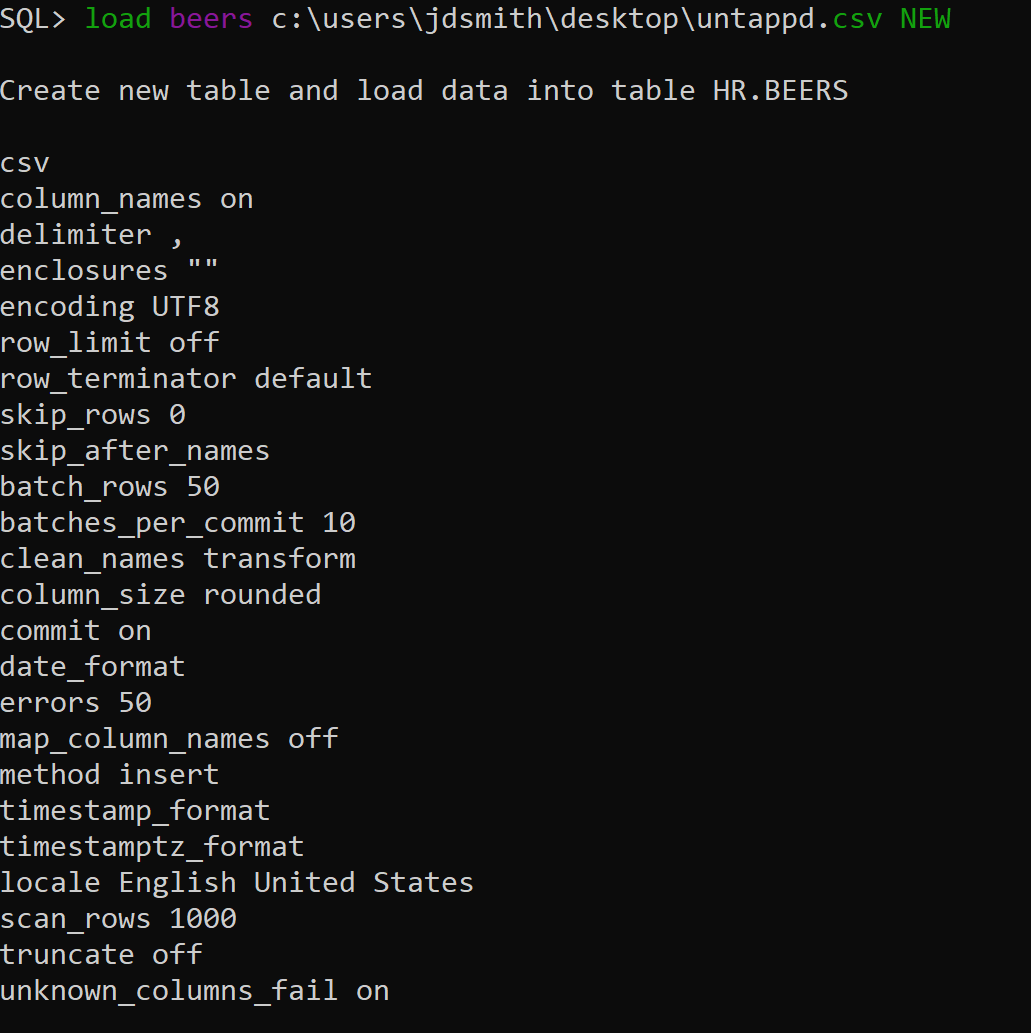
The most interesting thing of note here is this:
scan_rows 1000
That’s a LOAD command option telling SQLcl to look at the first 1,000 rows of my CSV to ‘measure’ the column widths and dates to build the DDL/INSERTs around.
If you have wider data past the first 50 or 100 rows, you’ll get a lot of REJECTED INSERTs.
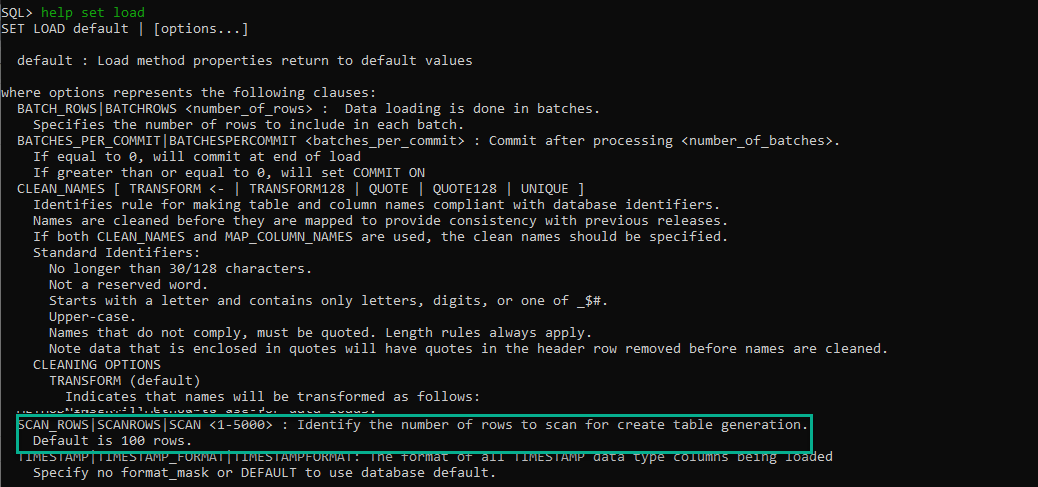
Note the higher you set this, the more resources you’ll burn reading the data and doing the number crunching.
So, I don’t need to do anything really, I can just toss my CSV at SQLcl, and let it put it into a table for me.
Here’s a quick animation…
Or maybe I just want the propose table DDL…
SHOW DDL, what’s that?
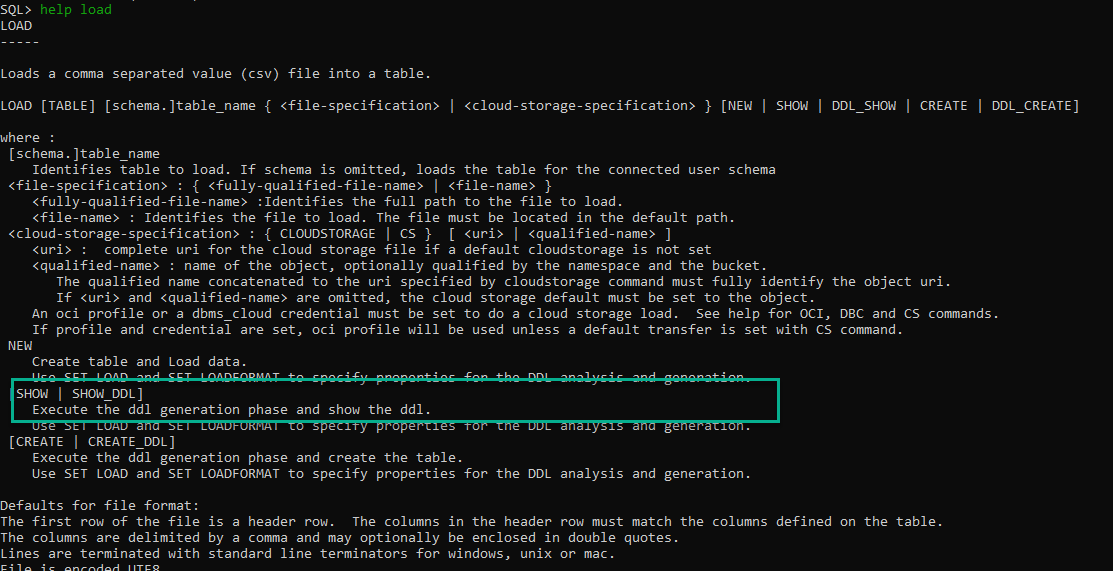
load newtable file.csv SHOW_DDL