
These aren’t “tricks” as everything I’m going to show you is documented. But these 3 ORDS REST API Tips will help save you some time and effort, I assure you!
These are all things I’ve previously discussed, but I wanted to string them together.
The ORDS REST API Tips
- Getting/Displaying JSON from Oracle TABLE Columns
- Using Query Filter parameters on any SQL based endpoint
- Controlling the number of records with LIMIT
The Data
I have a MOVIES table. Let’s look at it.
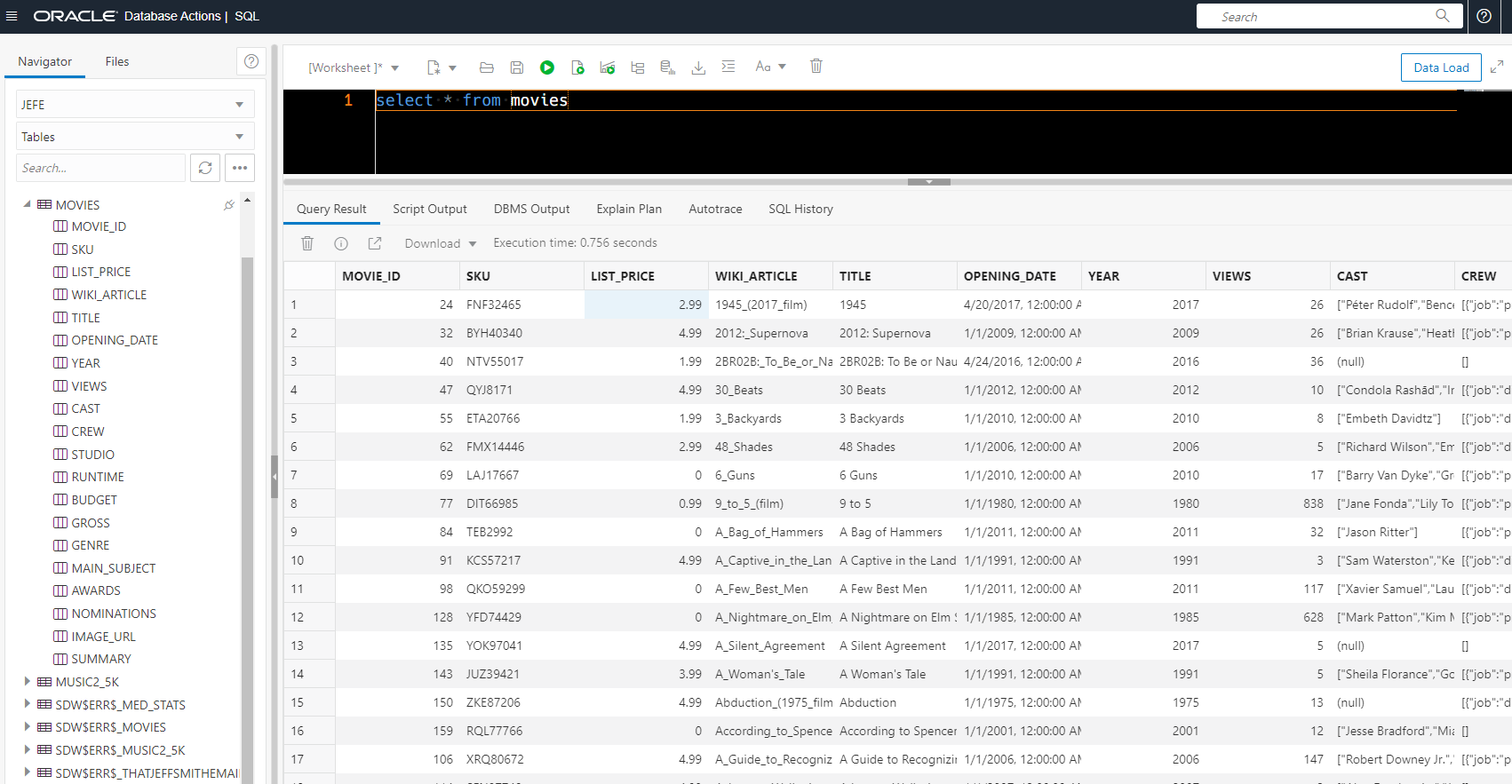
The actual DDL behind our table –
CREATE TABLE "MOVIES" ( "MOVIE_ID" NUMBER , "SKU" varchar2(4000) COLLATE "USING_NLS_COMP" , "LIST_PRICE" binary_float , "WIKI_ARTICLE" varchar2(4000) COLLATE "USING_NLS_COMP" , "TITLE" varchar2(4000) COLLATE "USING_NLS_COMP" , "OPENING_DATE" DATE , "YEAR" NUMBER , "VIEWS" NUMBER , "CAST" CLOB COLLATE "USING_NLS_COMP" , "CREW" CLOB COLLATE "USING_NLS_COMP" , "STUDIO" CLOB COLLATE "USING_NLS_COMP" , "RUNTIME" CLOB COLLATE "USING_NLS_COMP" , "BUDGET" CLOB COLLATE "USING_NLS_COMP" , "GROSS" CLOB COLLATE "USING_NLS_COMP" , "GENRE" CLOB COLLATE "USING_NLS_COMP" , "MAIN_SUBJECT" varchar2(4000) COLLATE "USING_NLS_COMP" , "AWARDS" CLOB COLLATE "USING_NLS_COMP" , "NOMINATIONS" CLOB COLLATE "USING_NLS_COMP" , "IMAGE_URL" varchar2(4000) COLLATE "USING_NLS_COMP" , "SUMMARY" varchar2(4000) COLLATE "USING_NLS_COMP" , CHECK ( CREW IS json ) enable , CHECK ( GENRE IS json ) enable , CONSTRAINT "MOVIES_PK" PRIMARY KEY ( "MOVIE_ID" ) USING INDEX ENABLE ) DEFAULT collation "USING_NLS_COMP";
A few CLOBs here, but only two have the CHECK “IS JSON” constraint. Those will be the only columns we can use our JSON simple DOT notation SQL against as I demonstrated in this post.
My REST API
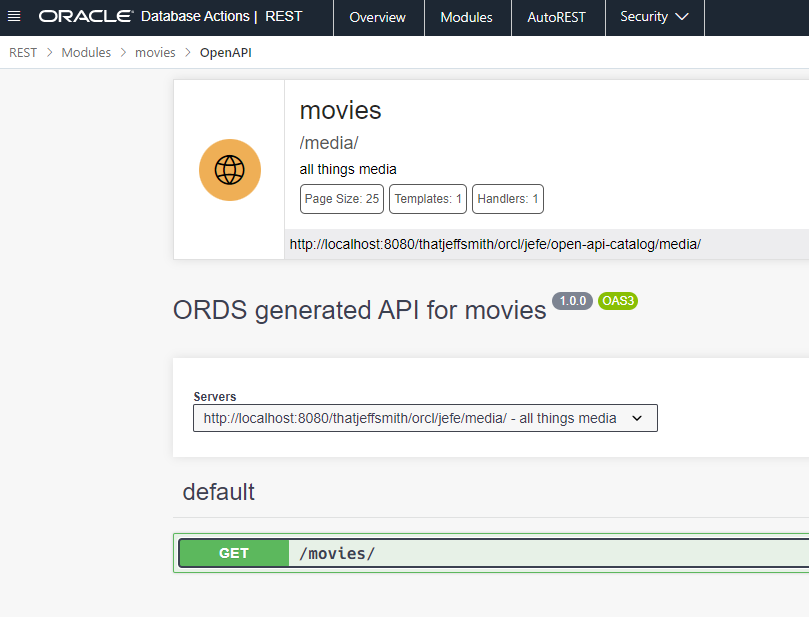
I’m using SQL to back this GET handler on movies/ –
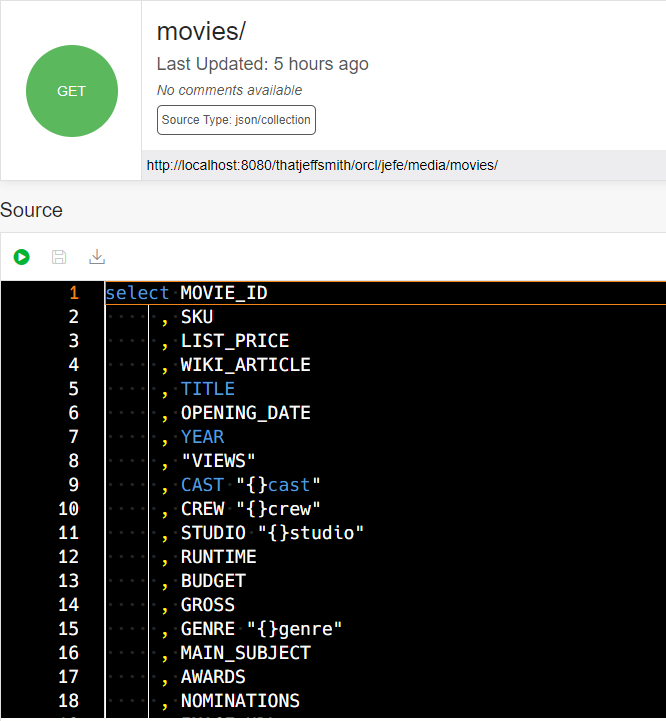
Trick #1 – dealing with the JSON columns
IS JSON check constraint or no, ORDS needs to KNOW that it’s getting JSON back from the database. There’s two ways you can do this in your SQL based REST APIs.
- using 21c or higher and the native JSON data type for the column
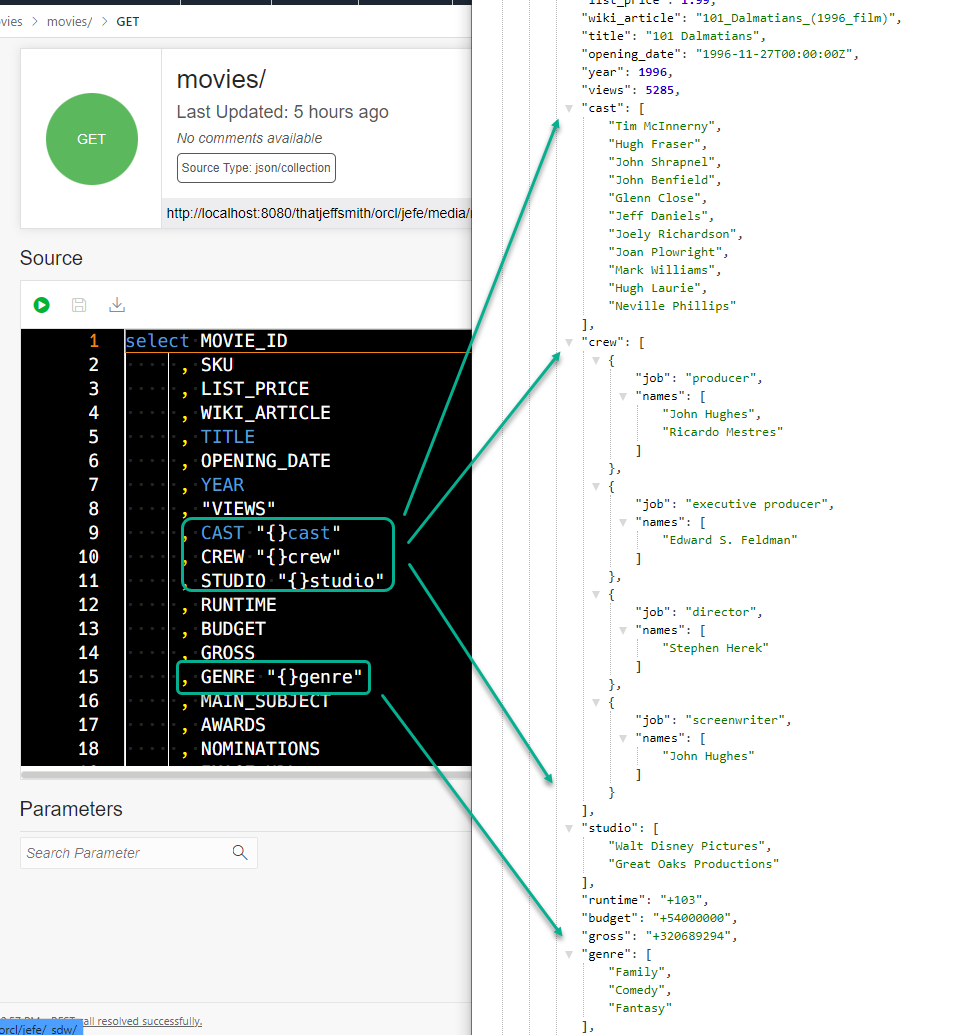
- using an “{}alias” for the column in the SELECT
I’m on 19c database in this example, so I’m left with option number 2. Let’s look at a before and after example.
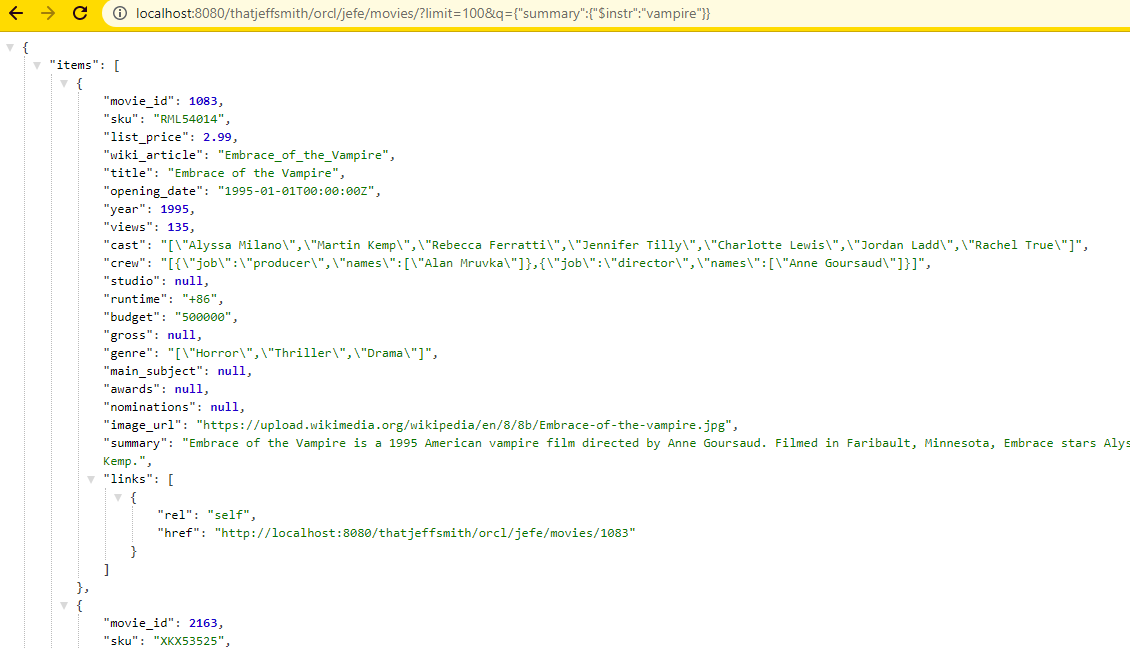
Now looking at the same result where I have added aliases for each column containing JSON.
More details – including examples for PL/SQL and native JSON data types.
Trick #2: Using Query Filter Parameters
Now you may be under the impression this is only available for the AUTOREST APIs, but that is far from the truth! If your API is backed by a SQL SELECT – you can do this!
GET /movies/
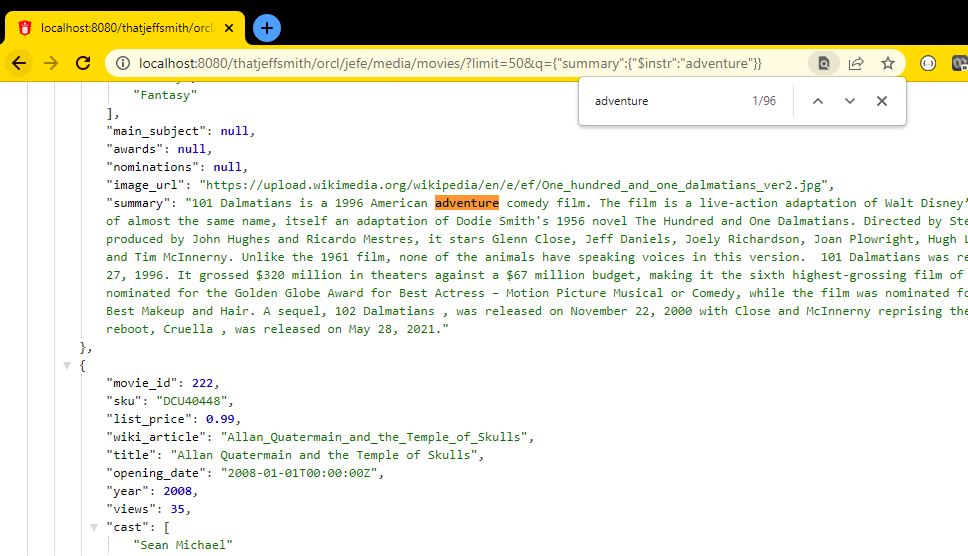
GET /movies/?q={"summary":{"$instr":"adventure"}}In the second case, instead of running JUST our SELECT query, ORDS ADDS an appropriate WHERE clause to our query.
It’s saying for the SUMMARY column in the table, look for the text, regardless of case, “adventure.”
Now, you MAY be tempted to just GET all the rows and process your JSON with your Python, JavaScript, whatever code in your mid-tier, browser, or app level. And, this could even work just fine.
But, what if your payload isn’t just 5 records, but 50,000? Let the database crunch that data for you, before it’s even returned to your app. This will run faster AND save you a lot of local CPU and pain.
Trick #3: Controlling how many records we get on each call
Now, I can set the default pagesize of a JSON response at the module and GET layers of my APIs. BUT, I can also OVERRIDE that on each request.
I simply add a LIMIT clause.
So I have LOTS of movies with the word adventure in the summary, and I’d rather get 50 records at a go.
GET /movies/?limit=50
So if I call this and scroll to the bottom…
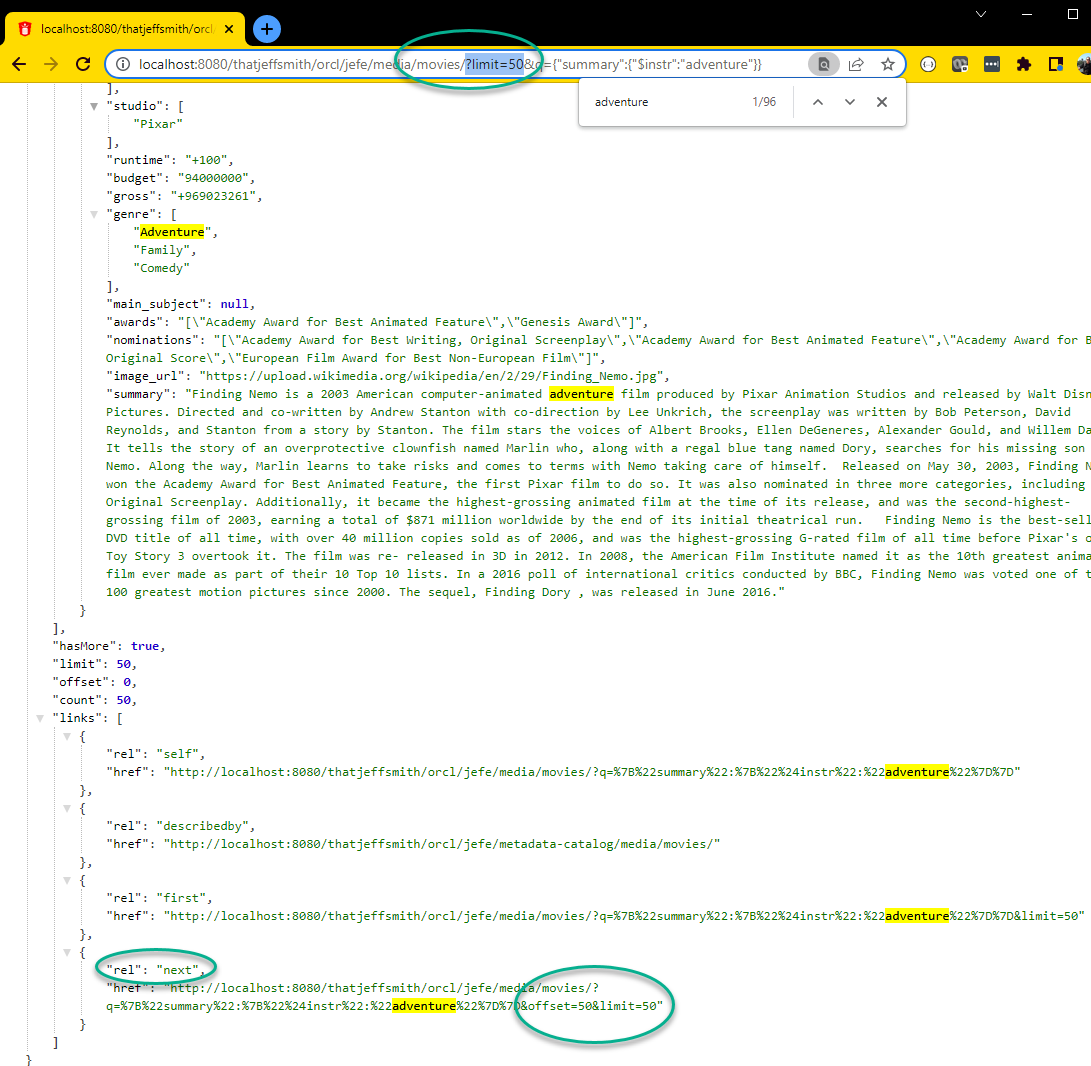
We can see that “limit” is set to 50, and that “hasMore” is set to true.
There’s actually 152 movies with ‘adventure’ in the summary out of my 3,000+ movies.




2 Comments
This is pretty awesome Jeff. Thank you!
Hey, thanks for sharing the feedback! Did you find this via my Tweet earlier today?