
I’m going to give my friend 4 files, that they can take and create in their Oracle Database, a
- an ITUNES table
- populated with about ~5k of my songs
- and a dumb little REST API
But wait, what’s the 4th file?
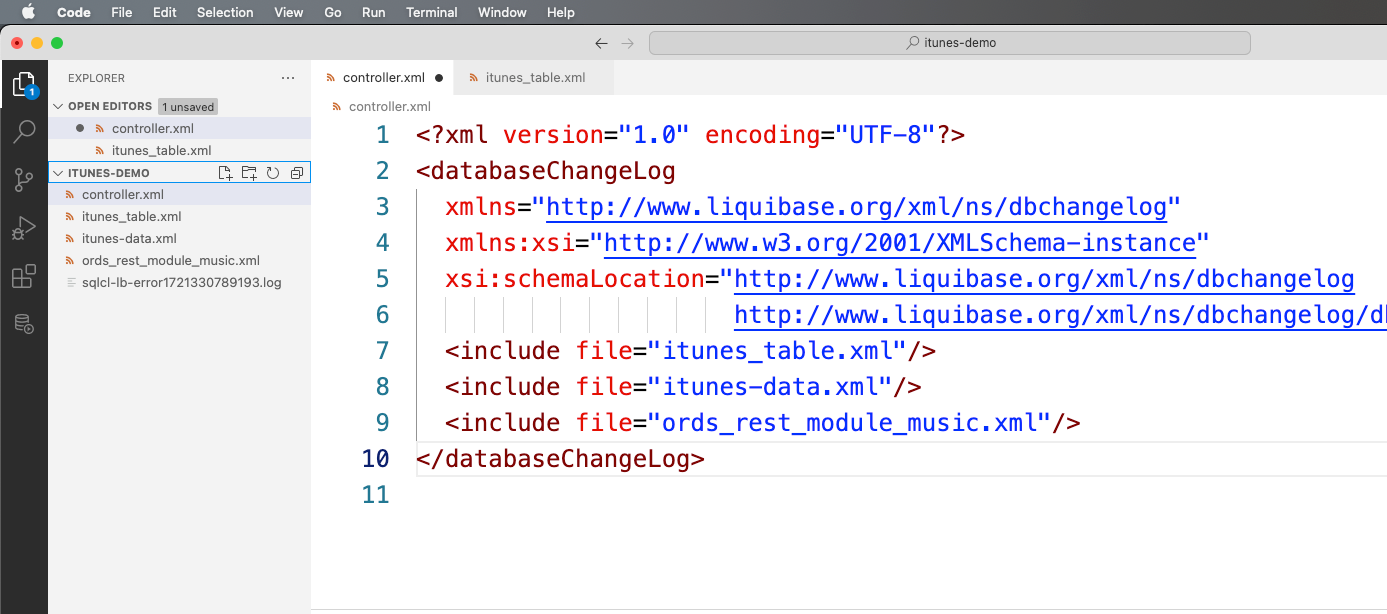
You can submit a collection of changeSets in a changeLog, my changeLog is defined with the 4th file, ‘controller.xml.’
Here’s what that looks like –
Today’s “trick” – we’re going to let SQLcl and Liquibase generate all these files for us.
I’m going to keep the typing to the ABSOLUTE minimum.
I already have the table created, populate, and it has the REST API going. I simply want to package it up for others to play with.
Yes, this tutorial already assumes your schema has been developed, and now we just want to represent it as a Liquibase changeLog. How to do your own iTunes table. For a more modern take, let’s consider Spotify.
Here’s a quick peek at what that looks like –
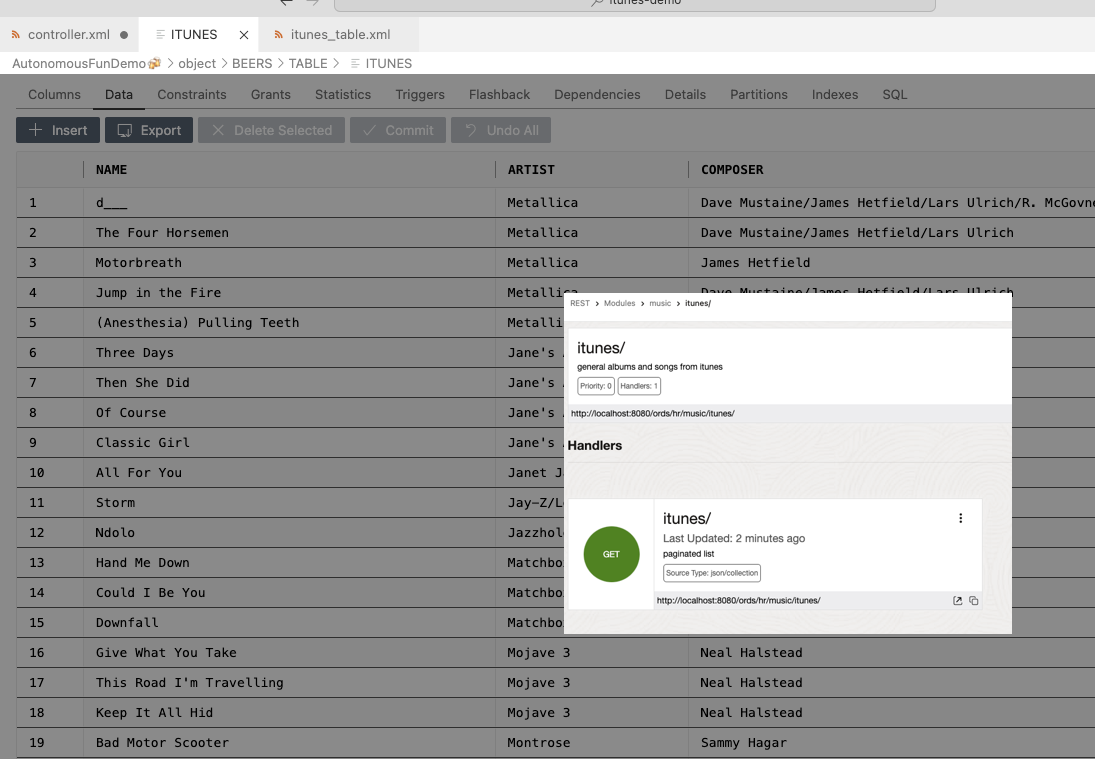
Step 1: Grab the table
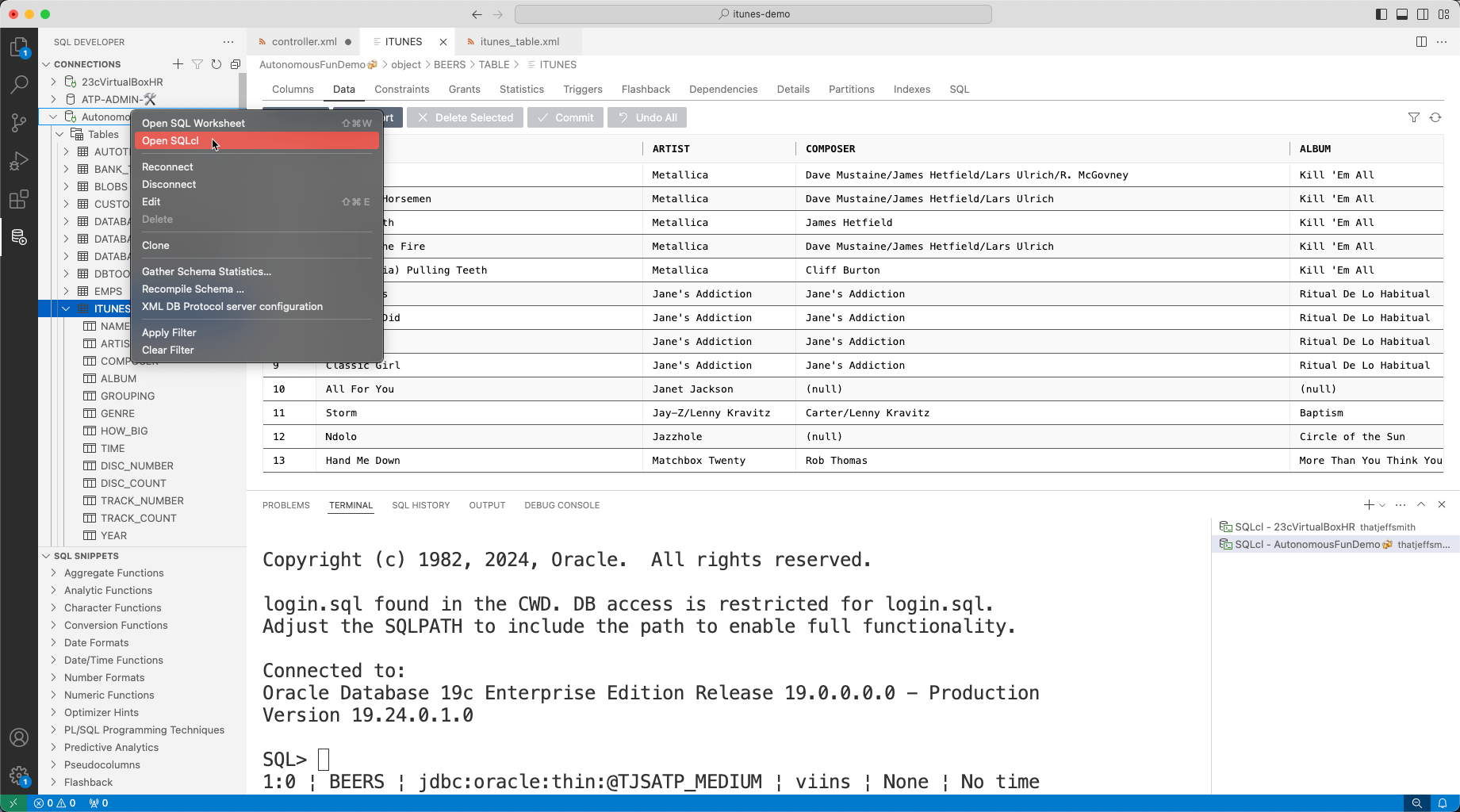
Since our SQL Developer extension for VS Code includes SQLcl, I’m going to be using it there. Another good reason, I’ll be using VS Code to tweak some of the XML files we’ll be generating.
On my source database, I simply right-click on the connection, and ask for a SQLcl terminal.
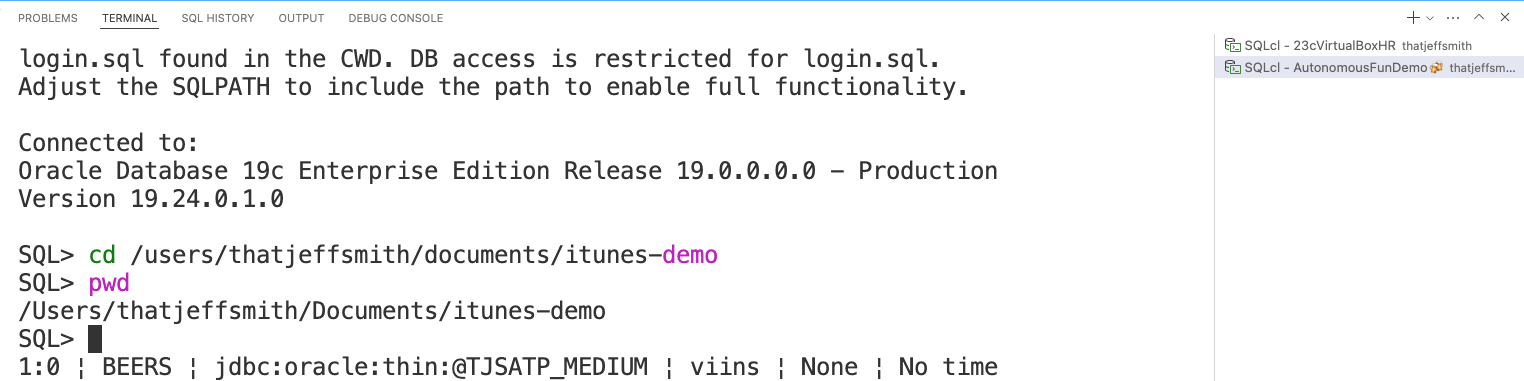
Step 1a: Create a working directory
I’m going to be putting these files into /users/thajeffsmith/documents/itunes-demo. So I’ll need to create this directory, and then simply use the ‘cd’ command in SQLcl to set the current working directory.
From here on out, any files I want to create or read, will be coming from this directory.
Step 1b: Generate the ITUNES table changeSet file
We’re going to generate an XML representation of the physical structure of our table, its list of columns, storage properties and more.
Here’s the command –
lb generate-db-object -object-type TABLE -object-name ITUNESIn SQLcl, as you’re typing out liquibase commmands, you can simply hit tab to get autocompletion help for both the subcommands and their parameters.
That looks like this –
Alright, enough of the fancy pancy, let’s just run the darned command. Note that if I wanted to have an accompanying SQL file, I simply add a -sql to the end, but I won’t and I didn’t.
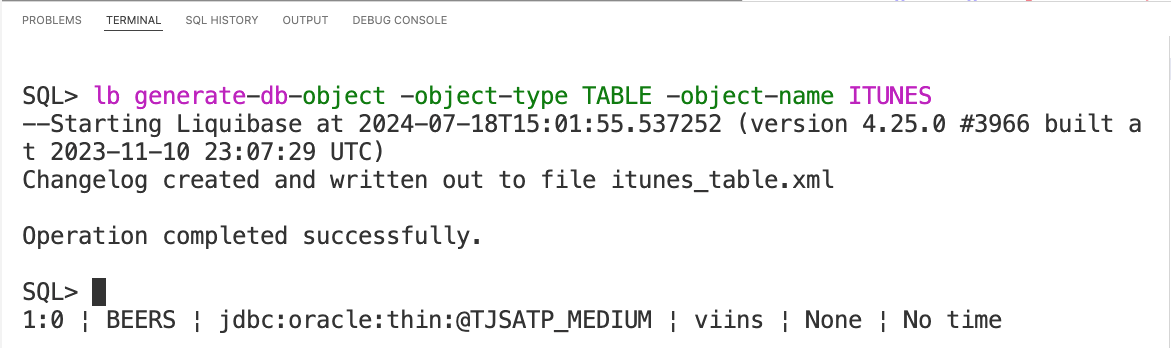
Step 1c: Is it good?
Maybe? Let’s take a look.
The XML file isn’t fun to look at, I mean, it’s XML. That’s a good reason to generate the optional SQL files, they’re much nicer for DIFFs and quick scans with your human eyeballs. But, I do see something ‘amiss.’
<PHYSICAL_PROPERTIES>
<HEAP_TABLE>
<SEGMENT_ATTRIBUTES>
<SEGMENT_CREATION_IMMEDIATE></SEGMENT_CREATION_IMMEDIATE>
<PCTFREE>10</PCTFREE>
<PCTUSED>40</PCTUSED>
<INITRANS>10</INITRANS>
<MAXTRANS>255</MAXTRANS>
<STORAGE>
<INITIAL>65536</INITIAL>
<NEXT>1048576</NEXT>
<MINEXTENTS>1</MINEXTENTS>
<MAXEXTENTS>2147483645</MAXEXTENTS>
<PCTINCREASE>0</PCTINCREASE>
<FREELISTS>1</FREELISTS>
<FREELIST_GROUPS>1</FREELIST_GROUPS>
<BUFFER_POOL>DEFAULT</BUFFER_POOL>
<FLASH_CACHE>DEFAULT</FLASH_CACHE>
<CELL_FLASH_CACHE>DEFAULT</CELL_FLASH_CACHE>
</STORAGE>
<TABLESPACE>DATA</TABLESPACE>
<LOGGING>Y</LOGGING>
...Not obvious enough?
How about this?
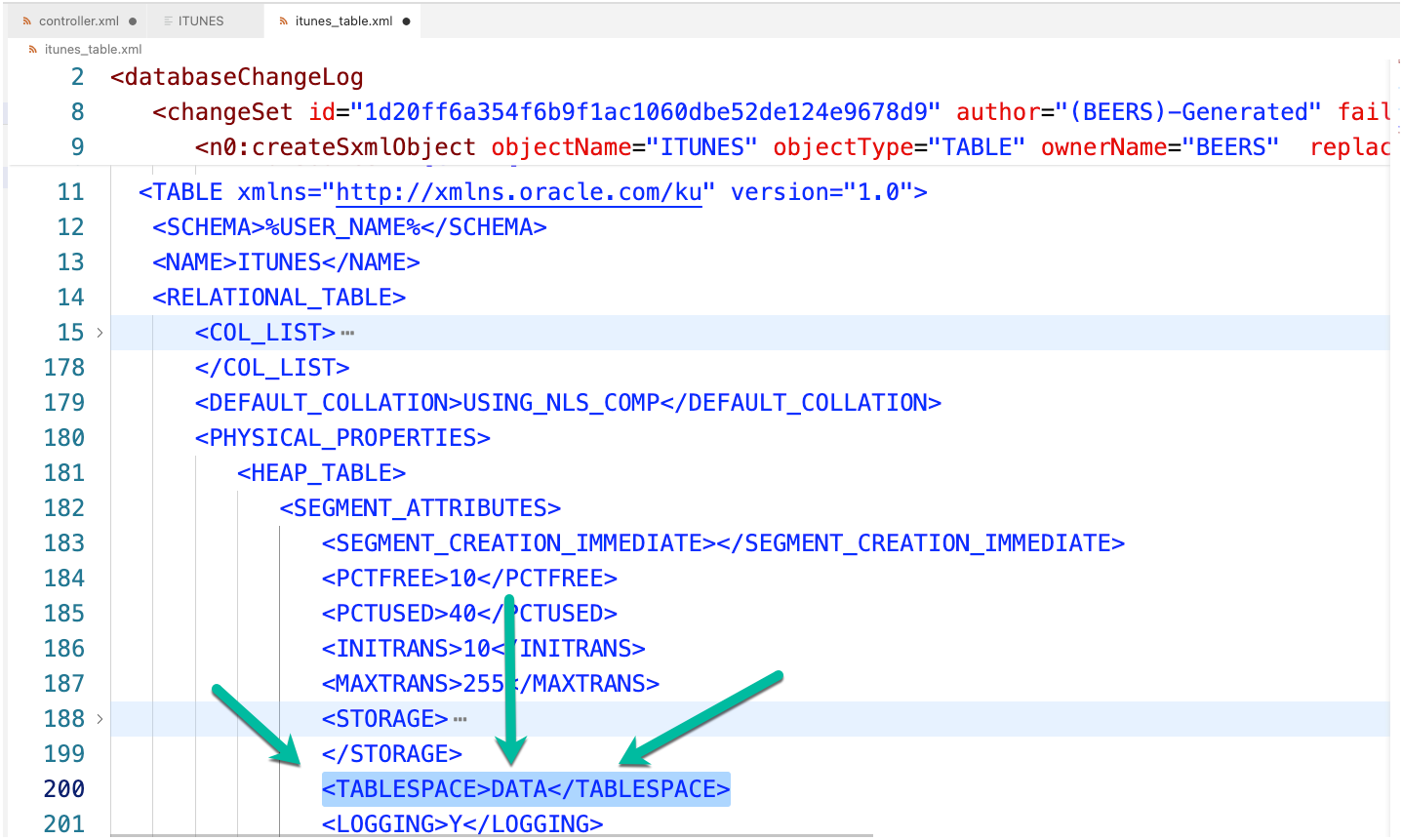
There’s nothing wrong here. Except, except that I know in the target instance there is no DATA tablespace, and the create table will fail if you try this.
Options?
Option 1: Just edit the file, silly.
Remove or replace the offending metadata bits with your keyboard.
Option 2: Adjust the runtime environment before grabbing the changeSet.
I can tell SQLcl to not worry about the tablespace, or even any of the segment attributes described in the physical properties section of this XML file.
set ddl tablespace off
set ddl segment_attributes offAfter this, just generate the changeSet again, and when we inspect the bottom section, we see the ‘physical properties’ bits are null. So when the update is applied on another system, we’l just inherit the default tablespace and its related settings for the schema.
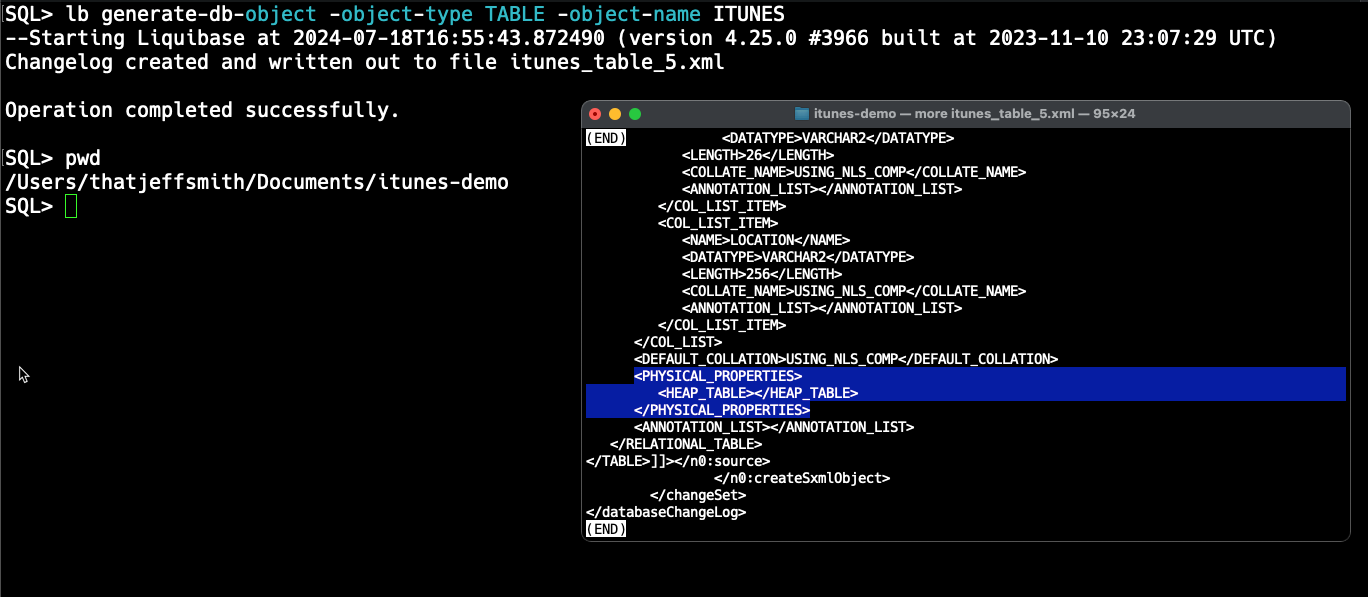
Step 2: Grab the data
My table has a bunch of rows in it. I want to include the data when I go to do an update using the changeLog on other systems.
The Liquibase community edition feature for auto-generating DATA changeSets is OK. You’ll see warnings generated from them that you’ll want to inspect the output and test things thoroughly, as it doesn’t necessarily support more advanced types of data. We here at Oracle have NOT enhanced this area of the Liquibase project, YET, but it is on our roadmap.
So I’m going to show you two alternatives here.
Step 2a: Using the liquibase data changeSet
lb data -ouf itunes-data.xml -include-objects ITUNESBy default Liquibase will grab ALL the data in the schema, we don’t want that, so we’re using the include filter, and saying which table we want, ITUNES.
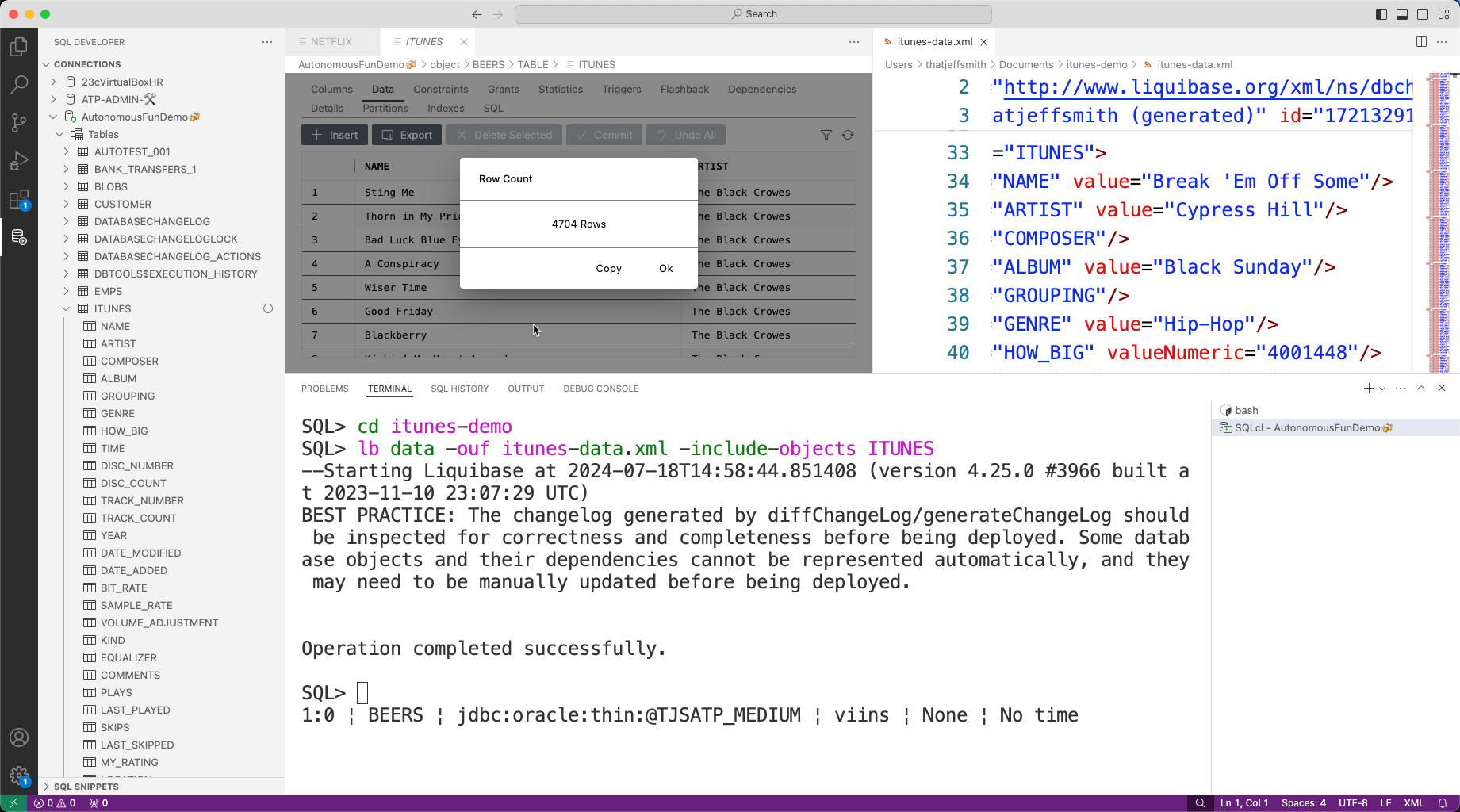
The resulting changeSet is an XML file with one child node per row in the table.
Alternative 2a: Using SQLcl UNLOAD or spool to CSV
We can instead take the rows in our table, store them in a CSV file, and then use a runOracleScript changeSet to run a SQLcl script to use the LOAD command to put the CSV back into our table.

If you’re going to be dealing with a lot of data, not just a simple look-up table for example, so many thousands or millions of records, I will tell you that Option 2 WILL BE more performant.
Step 3: Grab the REST API(s)
We have a liquibase generate command for REST Modules, so this is again, pretty easy.
First, find the list of modules available in your schema –
Simply run the ‘rest modules’ command from SQLcl:
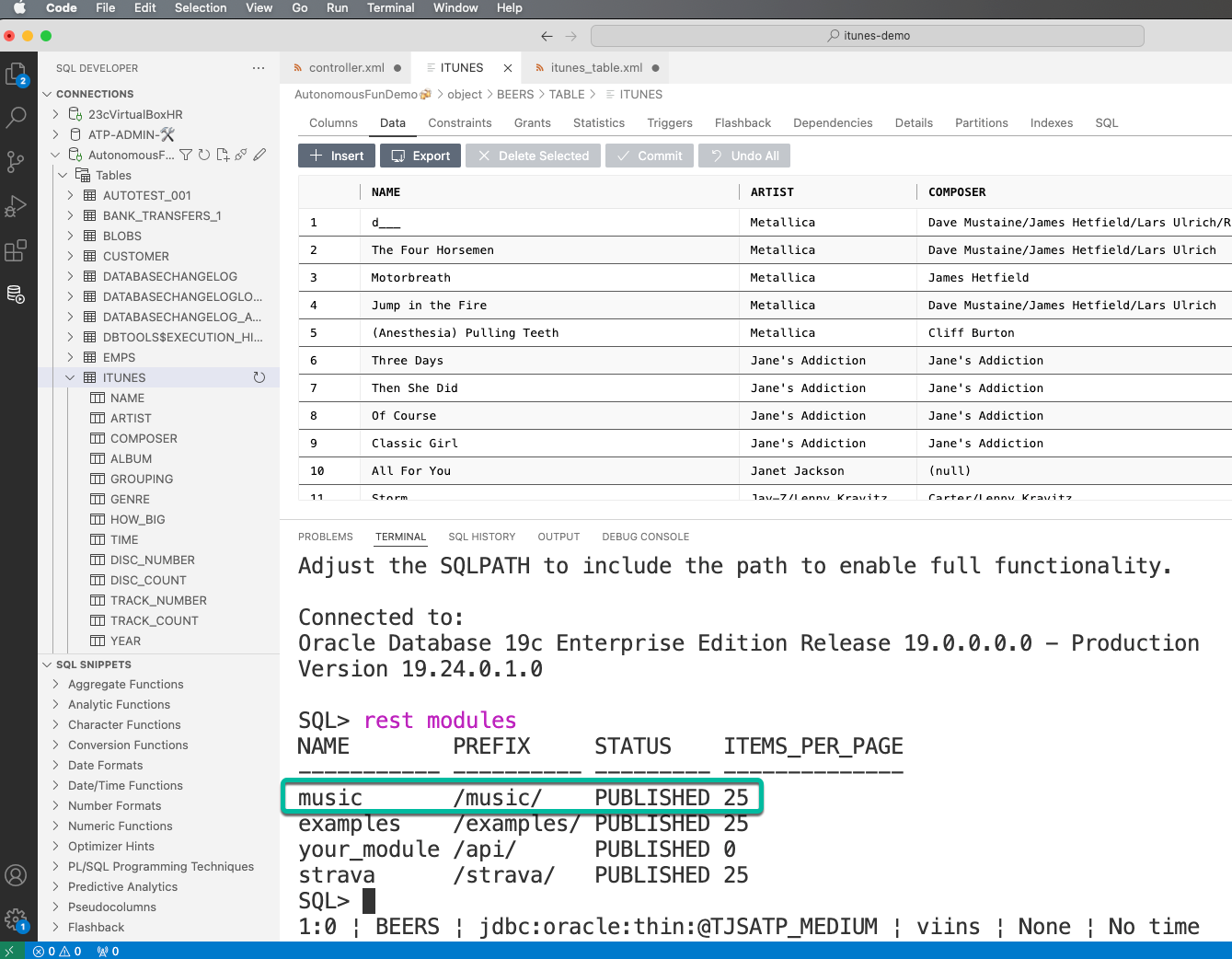
We only need the name for the next command –
lb generate-ords-module -module-name musicNote that there’s a bug on exporting REST modules in SQLcl 24.1, so make sure you’re on version 24.2 before running this.

The output is an xml file, ords_rest_module_music.xml.
Step 4: Putting it all together
We use a changeLog (Liquibase docs), controller.xml, file to ‘put it all together,’ literally where we provide the list of changeSets we want ran, in the order they should be executed.
Step 4a: Generate the controller
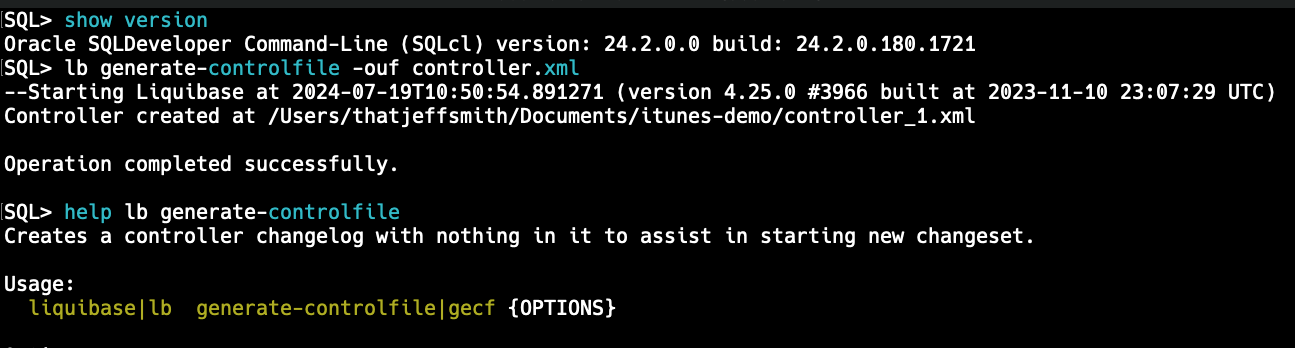
The controller.xml will just be an empty ‘shell’ – we need to add at a minimum, the list of changeSets we want to have applied, and in the order we want to apply them, specifically in this case –
<include file="itunes_table.xml"/>
<include file="itunes-data.xml"/>
<include file="ords_rest_module_music.xml"/> So it should look, more or less, like this –
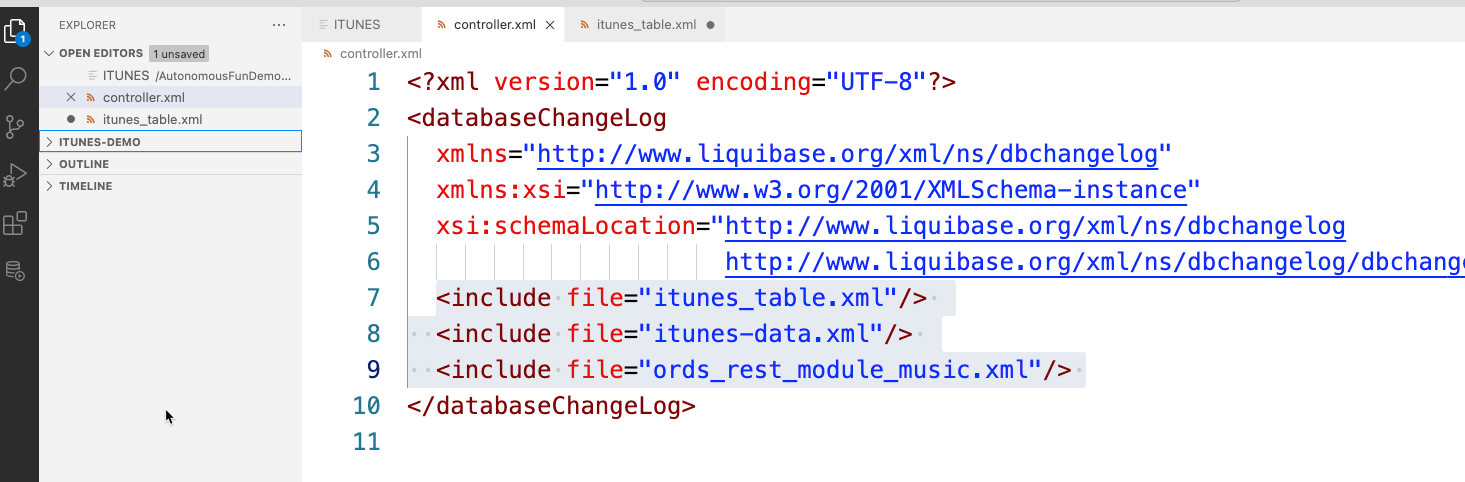
Let’s deploy and test our new changeLog!
I’ve been working on database X, and now I want to setup my table and REST API on database Y. I’m going to assume that ORDS is available on both, and that the target schema has already been REST enabled.
Login to the database, as the appropriate user. CD to our itunes-demo directory, and then run the liquibase update command, like so –
lb update -change-log-file controller.xml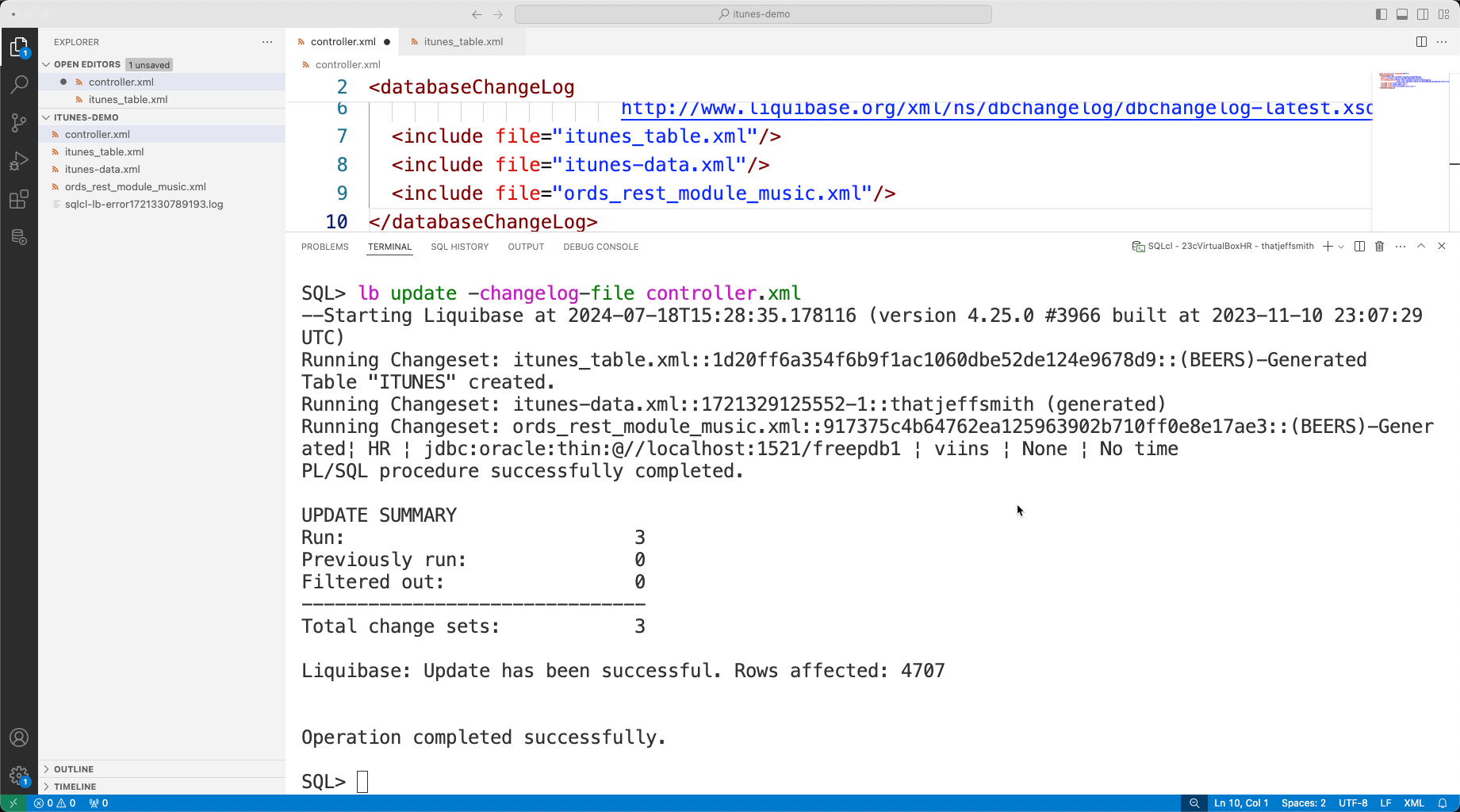
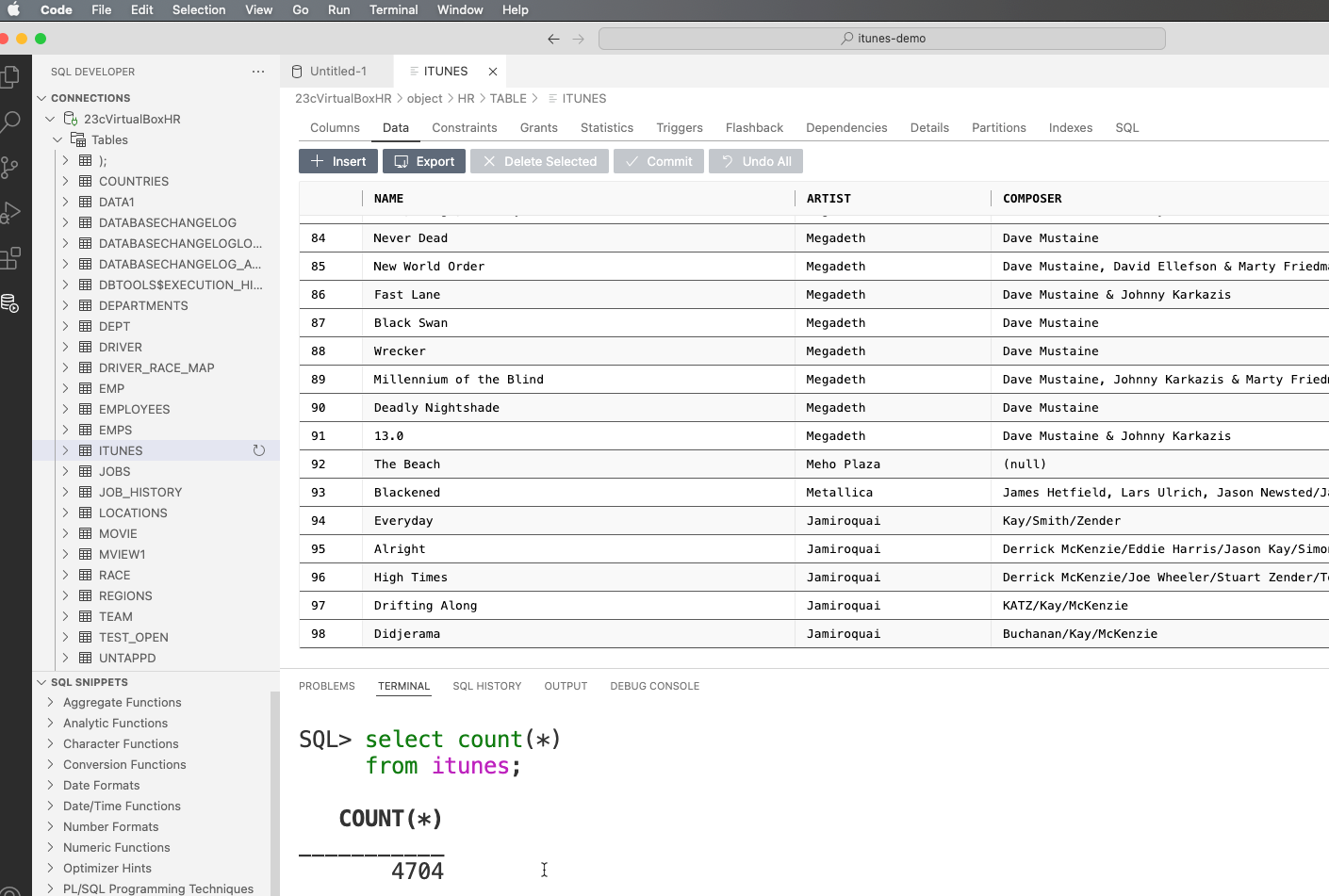
Let’s poke around a bit to make sure everything looks good.
I’ll do a select count(*) from our table, and then even browse it a bit…
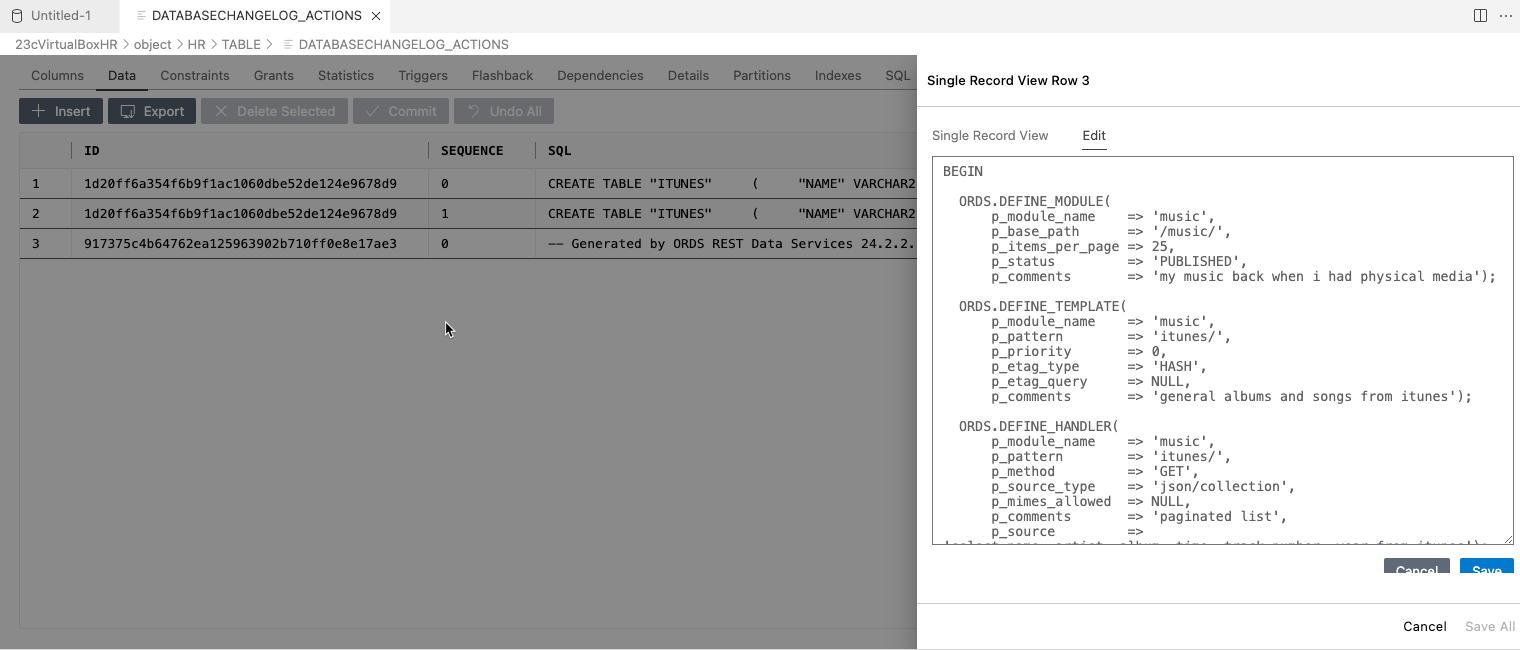
Let’s look at the databasechangelog_actions table – we record the SQL executed by changeSets we’ve put together, this won’t include any information for the DATA inserted:
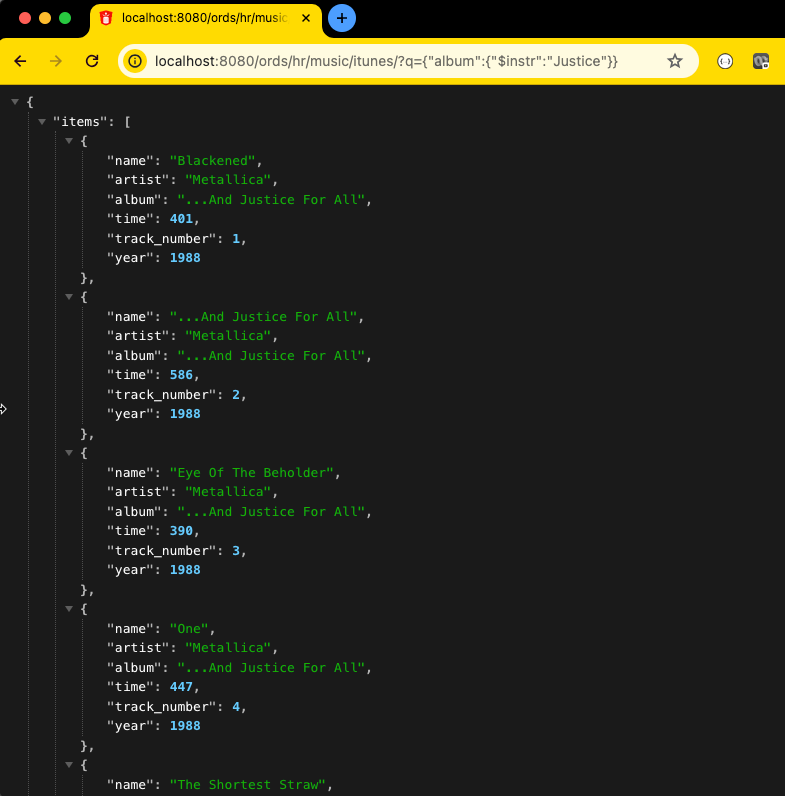
And finally if the module has been published, let’s test the API right quick –
Closing thoughts
This is a super simple example, with lots of human, hands-on keyboarding.
In the real world, your developers will be working in their development environments, and having these changeLogs captured or generated from using DIFFs from Liquibase or using our GENERATE commands. Those resulting changeSets will be going into a repository…where they will be put into a development pipeline for doing builds.
When a build ‘fails’ – the developer will get a notification, where they would check the offending changeSet, and ‘fix it’ – by submitting an updated set of files.
If this broken in a production pipeline, you would probably want to ‘fix it forward’ by generating a changeLog that addresses the current problem, but hopefully running the development and test pipelines for hundreds or thousands of iterations before they hit a production pipeline would mean this would be a rare exception case!



5 Comments
We can probably continue here https://forums.oracle.com/ords/apexds/post/sqlcli-liquibase-if-it-even-works-9747
I am using Liquibase from SQLCLI for the first time,
Anyway, I re-tried with SQLCLI 23.4.0.023.2321 on a freshly created schema – update worked.
Then I tried SQLCLI 24.1.0.087.0929 on the same target schema – update worked.
Eventually, I ran SQLcl 24.2.0.180.1721 on the same target schema – update failed with the same attempt of altering the DATABASECHANGELOG_ACTIONS, which still does not exist.
So, at least I can use some older SQLCLI at this point.
Can you get me the output from 24.2 with the -debug flag ?
Hi Jeff,
If you have a moment to look at this …
While trying to run LB UPDATE (from SQLCL), I constantly get “The specified table or view did not exist”
The log shows that the following statement was executed and failed
“ALTER TABLE SCHEMA.DATABASECHANGELOG_ACTIONS ADD CONSTRAINT DATABASECHANGELOG_ACTIONS _PK PRIMARY KEY (id,author,filename,sequence);”
The table indeed does not exist in the schema I connected, although DATABASECHANGELOG and DATABASECHANGELOGLOCK do exist.
SQLcl 24.2.0.180.1721
LB 4.25.0 #3966
Oracle DB 12.1.0.2
That table should be there if you’ve ever used sqcl to do an update.
Use the -debug flag to see what’s happening.