I’ve been talking quite a bit about JSON Relational Duality Views and the Multilingual Engine support for JavaScript in Oracle Database 23ai.
But, there’s another BIG feature that you may have heard about, our support for VECTORs.
Here’s my first foray into this new world! I’ll show you how I loaded a pre-built embedding generation model into the database, used that model to create some vectors, create a vector index, and use all of THAT to find some beers in my UNTAPPD library that have similar comments.
Here’s what you need to follow along
- 23ai Oracle Database, 23.4 or higher – I’m using our VirtualBox VM and 23.5
- DBA level privs to configure a few things
- Some interesting data
My data
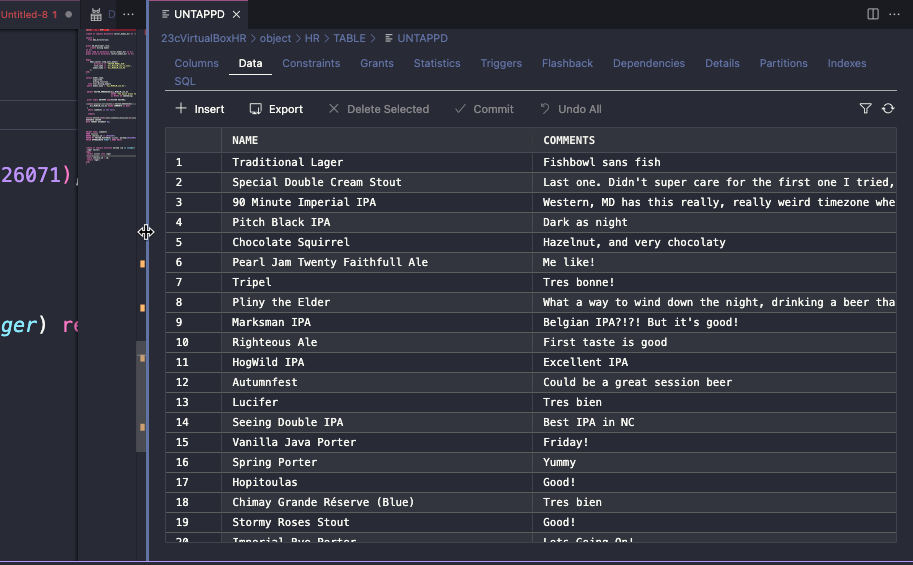
When I try a new beer, I log it with my social media app. One of the things I can add along with my rating, is a free form ‘comment.’ Those look like this –
What I thought, MIGHT be interesting, would be to generate some VECTOR data across my beer library, and then I could ask more interesting questions. So let’s dive into that!
Getting Started – loading our vector generation model
I’m brand new to all this stuff, so luckily I had a very nice blog post to follow along. Thanks to Sherry on our Oracle Machine Learning team for this lovely post!
You can add a sentence transformer courtesy Hugging Face and this pre-built ONNX resource for all-MiniLM-L12-v2.
Sherry shows it in her blog above, but I’ll confirm the steps here.
- Download transformer ZIP – it’ll be easier if you do this from your database server
- Unzip that to a new Database Directory
create the actual directory under $ORACLE_HOME, and then the associated database directory object –
create or replace directory vector_model_dir as ‘/opt/oracle/product/23ai/dbhomeFree/vectors’; - Grant access to the directory to your app user
grant db_developer_role, create mining model to hr;
grant read on directory vector_model_dir to hr;
grant write on directory vector_model_dir to hr; - Load the model – code below
- Confirm that it works!
begin
dbms_vector.load_onnx_model(
directory => 'VECTOR_MODEL_DIR',
file_name => 'all_MiniLM_L12_v2.onnx',
model_name => 'ALL_MINILM_L12_V2');
end;
/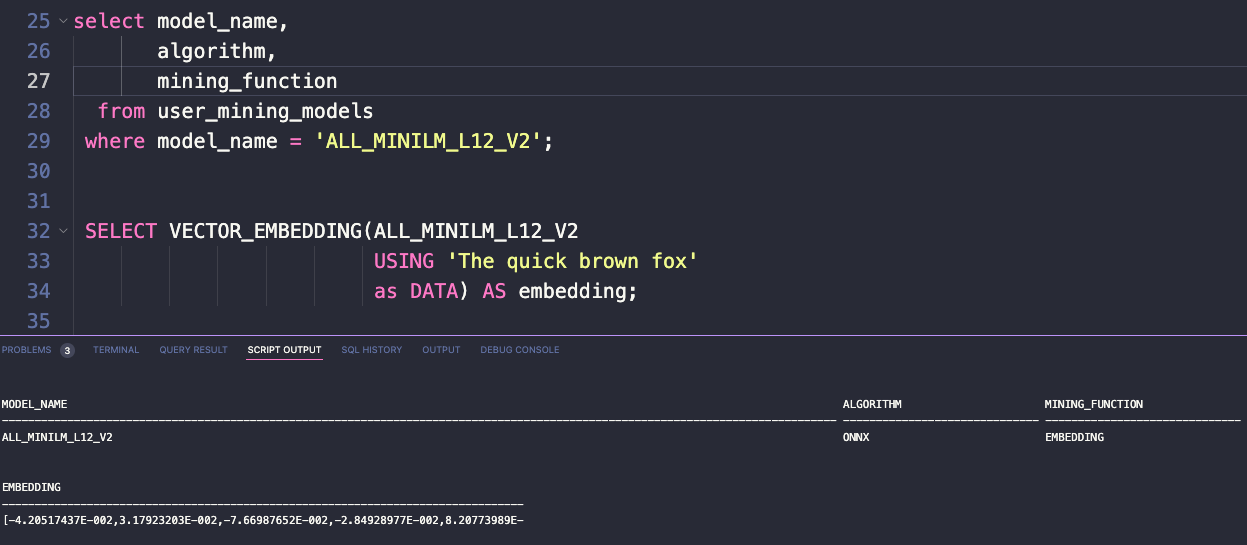
That first query shows that the model has been loaded. And the second query uses the VECTOR_EMBEDDING() function to send over a string, which returns a vector, based on that said model.
We could do the same thing locally with python, and load all those vectors into the database, but having the model available next to where all the data lives is so very convenient!
Next step, we gotta bounce the database
I mean, you don’t have to do this next step if you’ve already set aside some database memory for VECTOR ‘maths,’ but I’m going to guess you haven’t.
Login to your PDB as SYS or SYSTEM, and assign some space for VECTOR_MEMORY_SIZE, and then restart your database.
On my VirtualBox image, I’m going to go with 512 megs, and it seems to be ‘OK.’ I can always size that up or down as necessary.
alter system set vector_memory_size = 512M scope=spfile;Preparing our TABLE
You don’t have to do this, but you CAN do this. For my UNTAPPD table, I’m going to add a simple VECTOR column. We could instead compute these on-the-fly….but nah we’ll store it.
alter table UNTAPPD add(VICTOR VECTOR);Compute and populate the VECTOR & Index

This is where it gets fun and where I especially recommend you definitely read the VECTOR docs, because MATHS! I hope you enjoyed geometry in high school, because it’s back, baby!
In addition to the computed VECTOR for my beer diary comments, I’m also going to create a VECTOR INDEX for aiding in faster searches.
You trade the highest level of accuracy for faster results, but in many cases it’s most definitely worth it.
Generating the vectors and adding to the table
update untappd set victor = VECTOR_EMBEDDING(
ALL_MINILM_L12_V2 USING COMMENTS as data
)
where comments is not null;
commit;For every row in my table, where the COMMENTS column isn’t NULL, feed the COMMENTS data to the VECTOR_EMBEDDING() function.
My beer diary is big but not huge…approximately 2500 records. It took my database running on hardware from 2018 (so Pentium not ARM), about 18 seconds to do the work.
And now my UNTAPPD table looks like this –
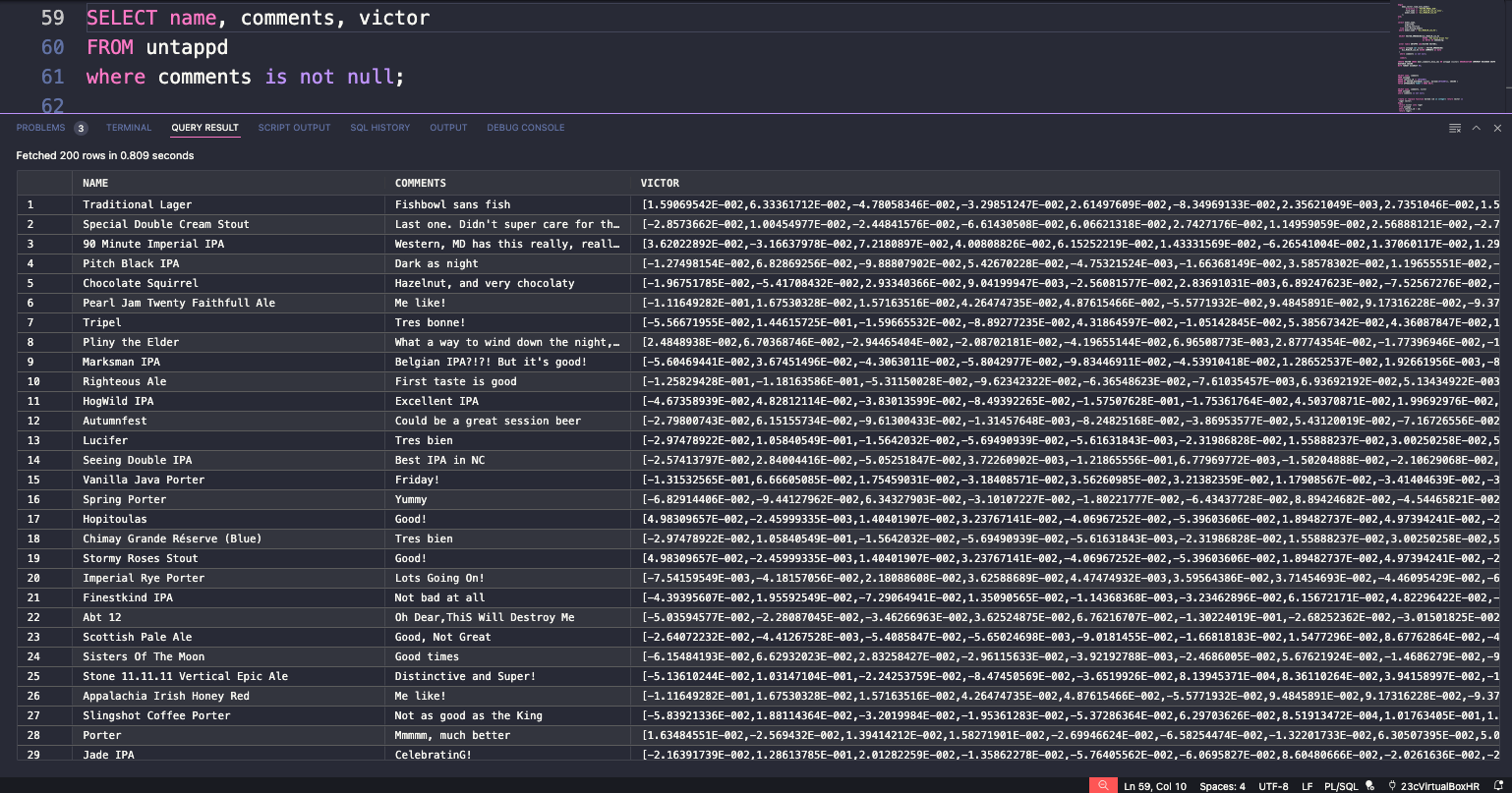
Here’s an idea of why a specialized VECTOR index might be useful here. Let’s look at just ONE of the computed VECTORs for my beer checkin comments.
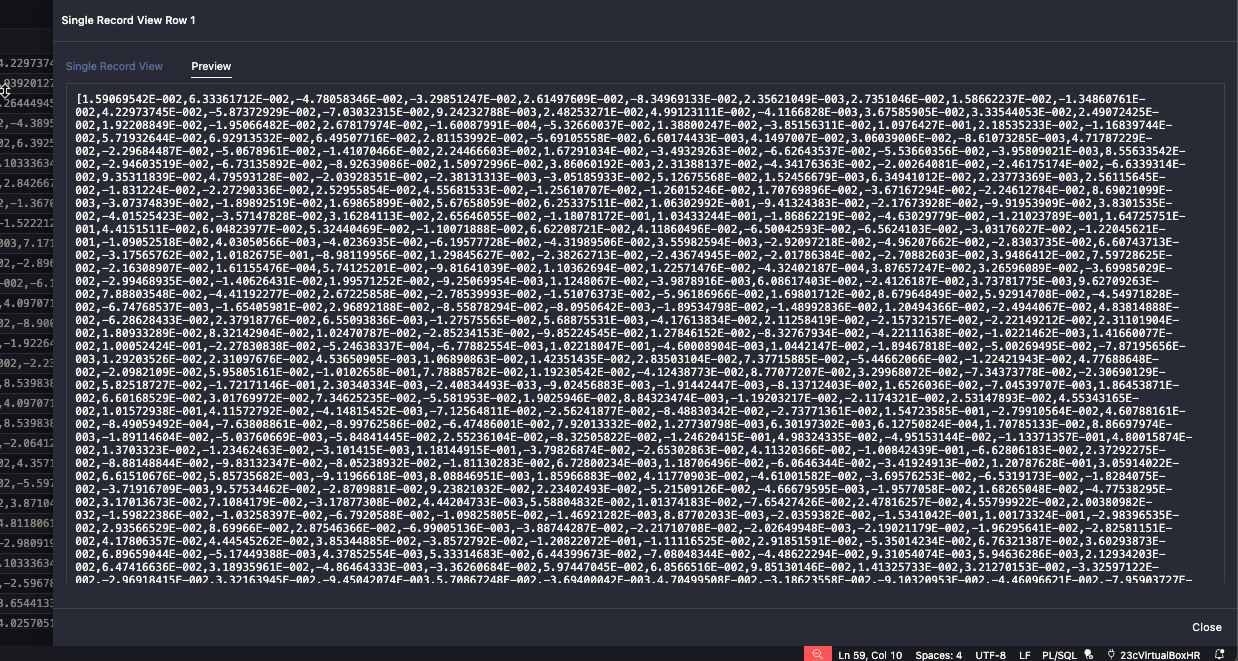
I ended up with 1,315 VECTORs added to my table.
Creating the INDEX
Those VECTORs are kinda chunky. Asking the DB to compute things based on such large amounts of data, having an INDEX available to cut the work down results in much faster answers.
CREATE VECTOR INDEX beer_comments_hnsw_idx ON untappd (victor) ORGANIZATION INMEMORY NEIGHBOR GRAPH
DISTANCE COSINE
WITH TARGET ACCURACY 95;I pulled this directly from the VECTOR docs demonstrating how to do approximation searches.
If you paid attention to the step above about setting up the VECTOR memory space, you’ll see that the INDEX is created in several seconds (3.5 in my case), and if you didn’t, you MIGHT end up with a ORA-5195.
If you do run into the ORA-5195 error, my fellow Oracle Database product manager Martin Bach has some great advice on the forums!
Now we can start asking questions!
I saw this example in the docs, and I think it’s close to what I wanted to do with my beer checkin comments.
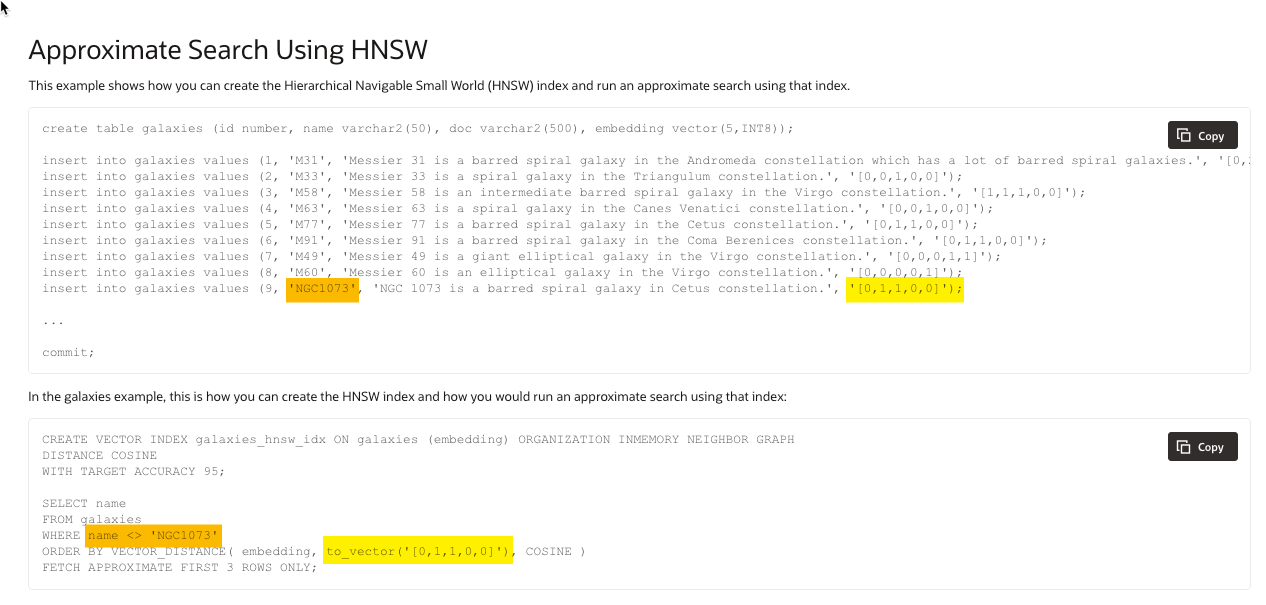
It has you add some basic VECTOR data, and then uses one of those values as a SEED to the VECTOR_DISTANCE() function. The ‘close’ two vectors are, the more likely they satisfy our desire to find something that’s like…the thing we’re looking at.
A fun example of this is using pictures (find me pictures having a bridge in it), but I’m going with strings here because it’s easier and this is my ‘Hello World!’
The example query is excluding the basis of the comparison, otherwise the database will say, hey have I got a good match for you!
So here’s my version of that same question/query –
SELECT name, comments
FROM untappd
WHERE checkin_id <> 107426071
ORDER BY VECTOR_DISTANCE( victor, kareem(107426071), COSINE )
FETCH APPROXIMATE FIRST 5 ROWS ONLY;UNTAPPD is obviously the beer table, and the vector data is stored in the VICTOR column. I picked a particular record as a starting point for the comparison –
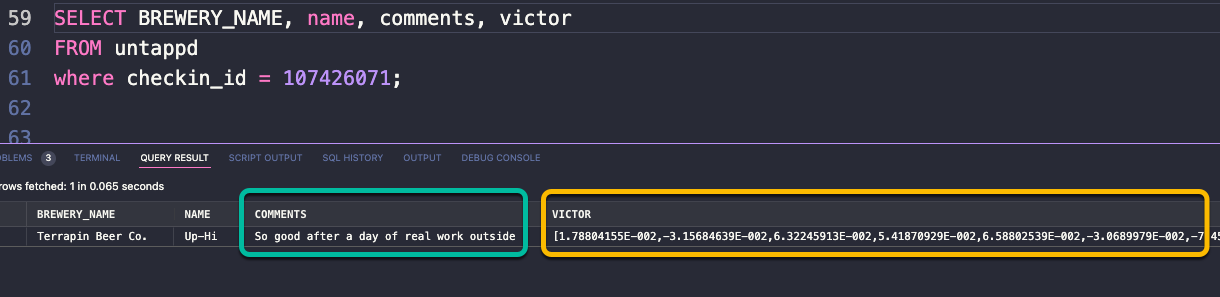
“So good after a day of real work outside” – there’s some sentiment there of interest. Could I find other times I checked into UNTAPPD with a similar thought or vibe? And the value I need to pass to the VECTOR_DISTANCE function is the associated vector value.
But wait, what or who is ‘kareem?’
Kareem is the PL/SQL function that lets me pass in an UNTAPPD record by primary key, and it returns the associated VECTOR value.
create or replace function kareem (id in integer) return vector is
roger vector;
begin
select victor into roger
from untappd
where checkin_id = id;
return roger;
end;
/Roger is the pilot character’s name in Airplane, and Victor the co-pilot, is played by Kareem Abdul-Jabbar.
I could have implemented this into the query itself via an inline function defined via WITH clause, but maybe I want to use that FUNCTION again, somewhere else.
Ok, let’s see the diary notes that are similar to ‘So good after a day of real work outside’
Note that I consider the work I do inside to be real work, but not as rewarding as the beer feels after 3-4 hours of yard work around the house.
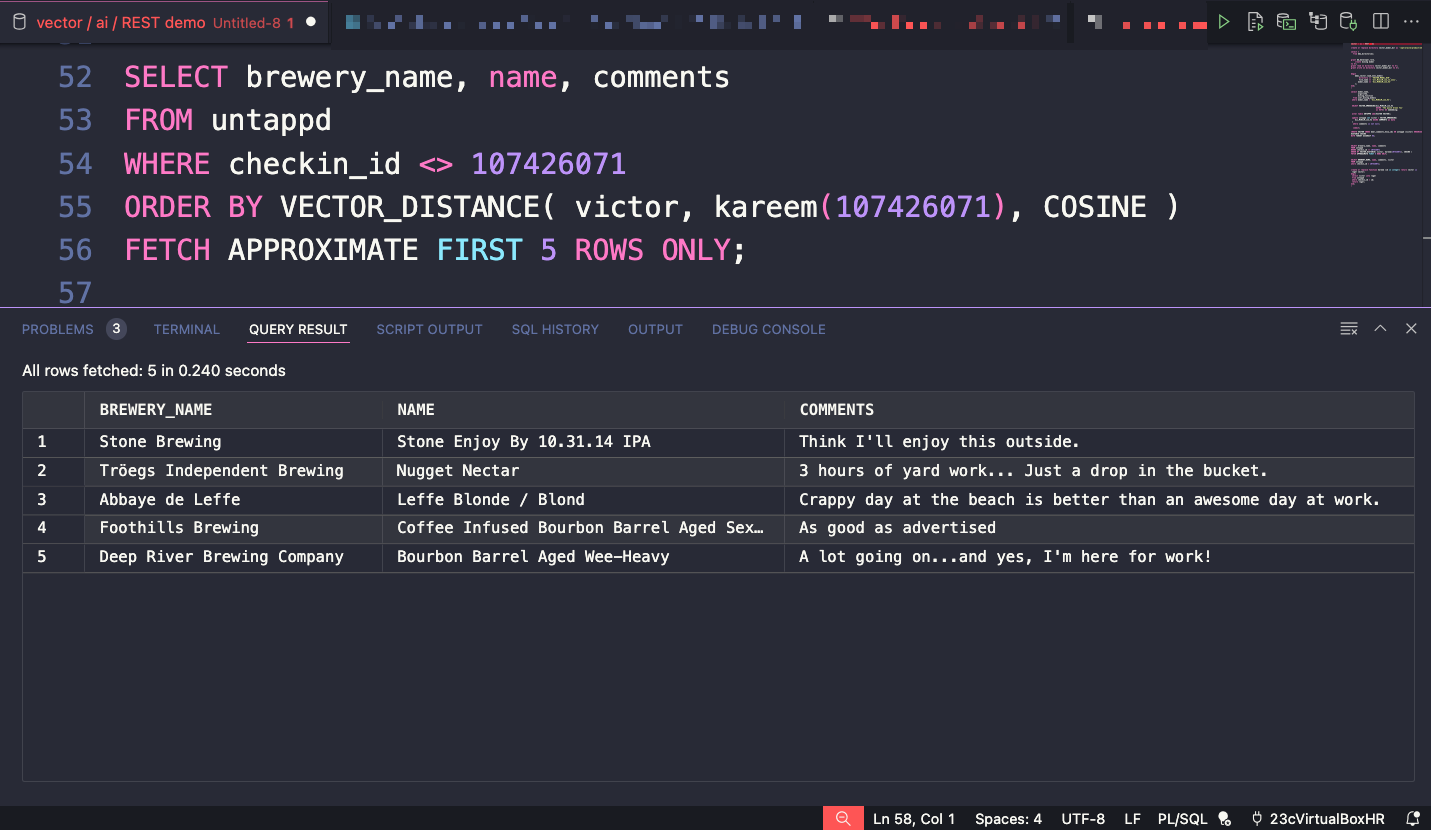
I think the first 3 hits definitely hit the same vibe or feels captured by the comparison point.
Shall we try another?
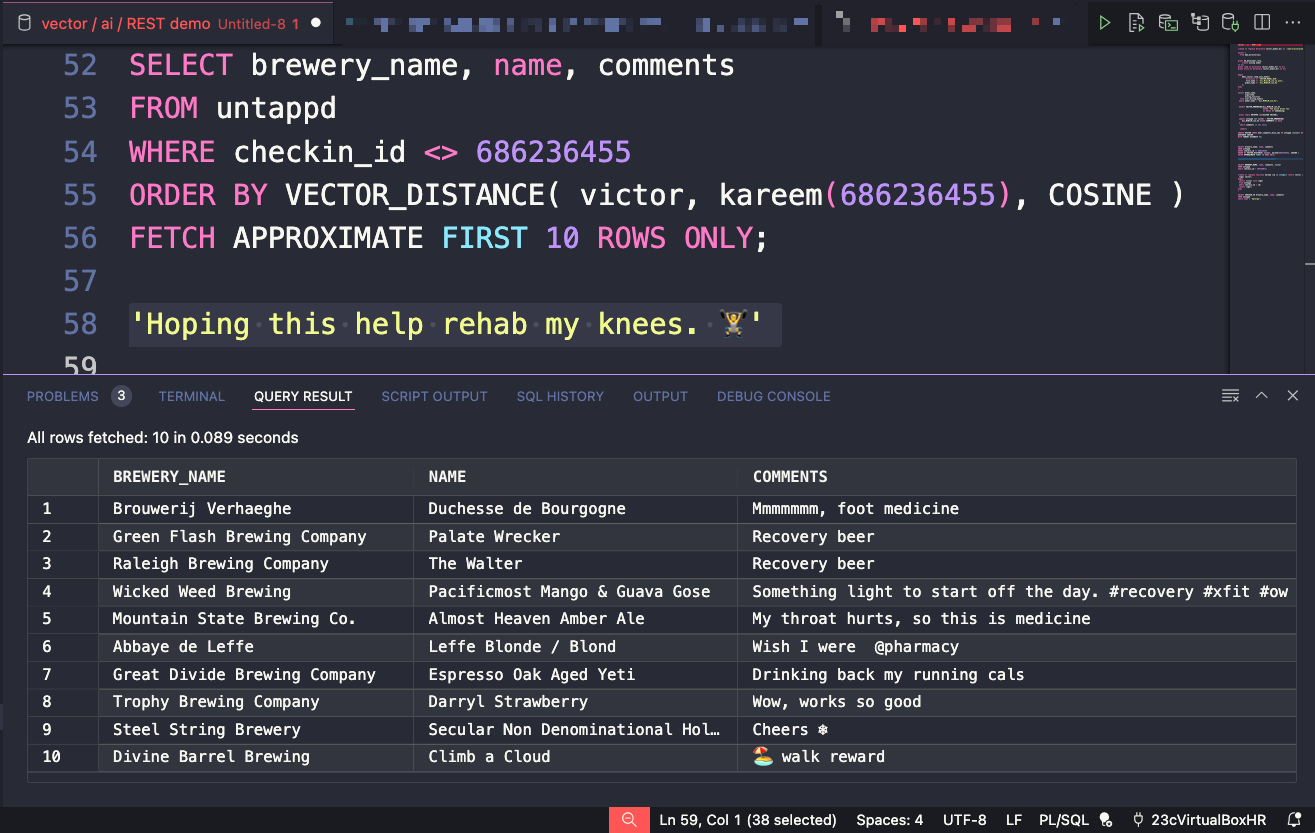
‘Hoping this help rehab my knees.  ’ – ok the CHECKIN_ID for that beer was 686236455, so let’s run that query again, but this time we’ll grab the nearest 10 vectors –
’ – ok the CHECKIN_ID for that beer was 686236455, so let’s run that query again, but this time we’ll grab the nearest 10 vectors –
Remember that INDEX, let’s check the plan…
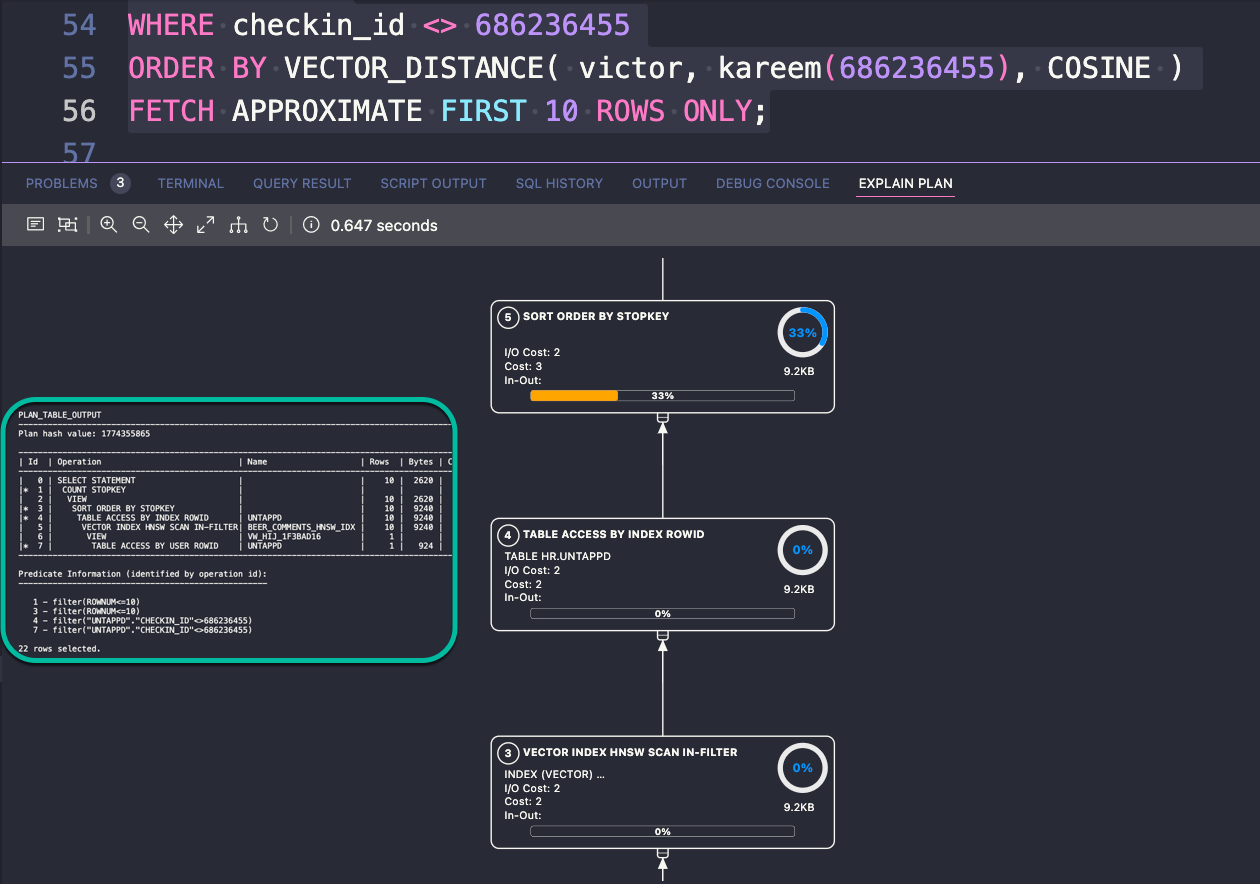
What’s a ‘VECTOR INDEX HNSW SCAN IN-FILTER?’ You’ll want to read up on the new plans steps when using these indexes in our Optimizer Plans for HNSW
Parting thoughts
I’m truly a NOOB here when it comes to VECTORs and using things like sentence transformers. I was able to read 1 blog post, and 2 sections of the 23ai docs, to do what I showed above in about 30 minutes.
It took me much longer to collect my thoughts and write this blog post.
And maybe the nicest thing for the moment, I didn’t have to write any Python, C, or Java to do this – ONLY SQL!
I think a much more interesting data set would probably be my tweets (sorry, X posts), but I’ll leave that for another day. Look for follow-up posts on this topic with some REST API examples!