I learn things like most of you:
- reading (blogs!)
- doing the thing
- and most likely by doing the thing I read about in a blog
I’ve been trying to keep up with AI Vector Search in 23ai (yes, I am but a mere human), and one of the new concepts to me, is Hierarchical Navigable Small World (HNSW) Indexes.
The blog I’m currently reading is from our product manager Andy Rivenes, Using HNSW Vector Indexes in AI Vector Search.
I’m hoping to be able to understand better what my execution plans are telling me when I start comparing vectors using these new types of indexes, for example –
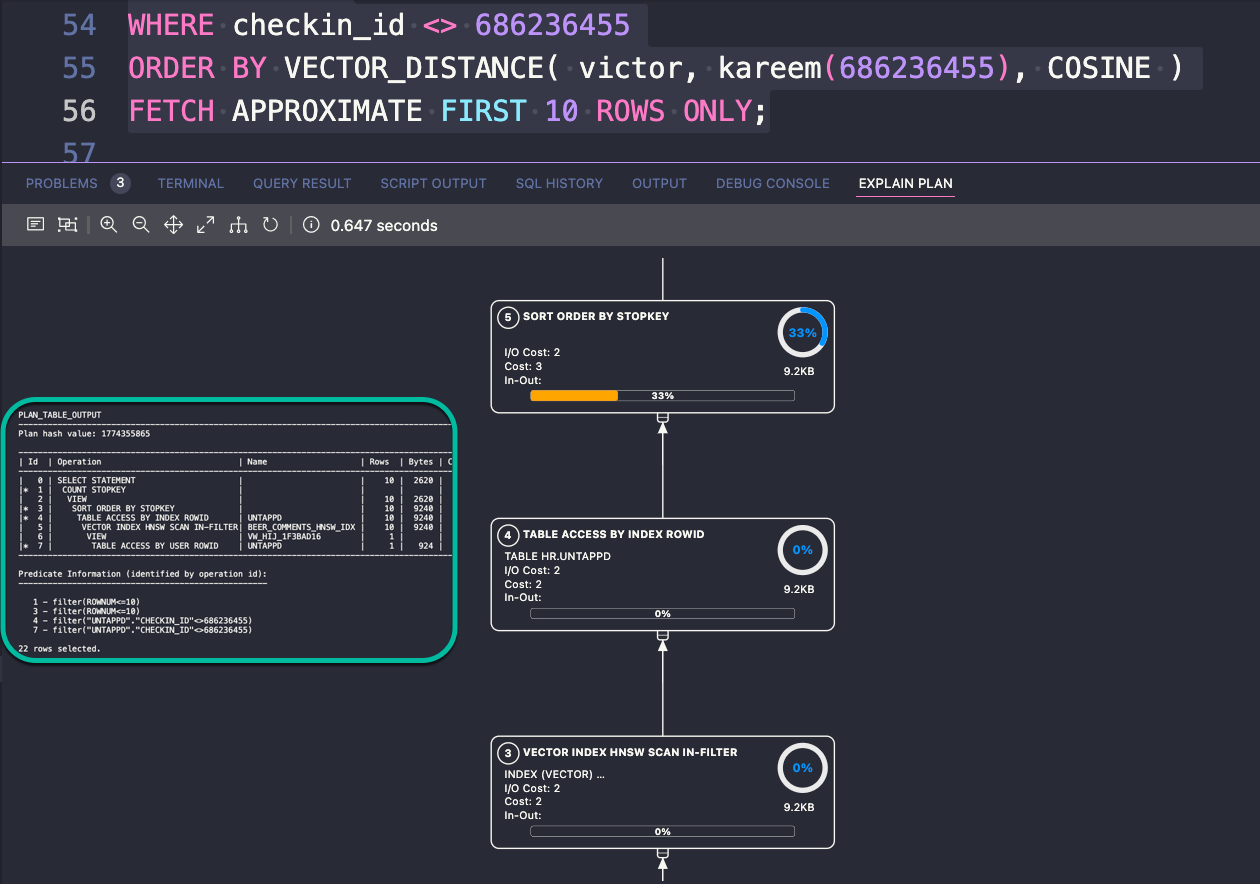
Andy’s HNSW post is using this data set, let’s load it!
Chicago’s Data Portal has a Crimes 2001-Present data set, and I’m going to download the CSV version of that.
Once it’s downloaded, here’s the general take I do.
Spark up SQLcl, use the LOAD command to generate some DDL
I’m going to use the ‘CD’ command to jump to my downloads folder, and then I’m going to use the LOAD command with the ‘SHOW’ keyword to just ‘show me’ what the LOAD command would do with this new CSV data if it were to be turned into a table.
Note I’ve done zero setup, this is just my ‘hey, maybe this will be good enough, attempt.’
SQL> cd /users/thatjeffsmith/downloads
SQL> load crime_data chicago-crimes.csv show
csv
column_names on
delimiter ,
enclosures ""
double
encoding UTF8
row_limit off
row_terminator default
skip_rows 0
skip_after_names
Show DDL for table HR.CRIME_DATA
#INFO COLUMN 2: Case Number => CASE_NUMBER
#INFO COLUMN 3: Date => DATE$
#INFO COLUMN 4: Block => BLOCK
#INFO COLUMN 6: Primary Type => PRIMARY_TYPE
#INFO COLUMN 7: Description => DESCRIPTION
#INFO COLUMN 8: Location Description => LOCATION_DESCRIPTION
#INFO COLUMN 9: Arrest => ARREST
#INFO COLUMN 10: Domestic => DOMESTIC
#INFO COLUMN 11: Beat => BEAT
#INFO COLUMN 12: District => DISTRICT
#INFO COLUMN 13: Ward => WARD
#INFO COLUMN 14: Community Area => COMMUNITY_AREA
#INFO COLUMN 15: FBI Code => FBI_CODE
#INFO COLUMN 16: X Coordinate => X_COORDINATE
#INFO COLUMN 17: Y Coordinate => Y_COORDINATE
#INFO COLUMN 18: Year => YEAR
#INFO COLUMN 19: Updated On => UPDATED_ON
#INFO COLUMN 20: Latitude => LATITUDE
#INFO COLUMN 21: Longitude => LONGITUDE
#INFO COLUMN 22: Location => LOCATION
CREATE TABLE HR.CRIME_DATA
(
ID NUMBER(10),
CASE_NUMBER VARCHAR2(26),
DATE$ VARCHAR2(128),
BLOCK VARCHAR2(128),
IUCR VARCHAR2(26),
PRIMARY_TYPE VARCHAR2(128),
DESCRIPTION VARCHAR2(128),
LOCATION_DESCRIPTION VARCHAR2(128),
ARREST VARCHAR2(26),
DOMESTIC VARCHAR2(26),
BEAT VARCHAR2(26),
DISTRICT VARCHAR2(26),
WARD NUMBER(4),
COMMUNITY_AREA NUMBER(4),
FBI_CODE VARCHAR2(26),
X_COORDINATE NUMBER(9),
Y_COORDINATE NUMBER(9),
YEAR NUMBER(6),
UPDATED_ON VARCHAR2(128),
LATITUDE NUMBER(13, 9),
LONGITUDE NUMBER(13, 9),
LOCATION VARCHAR2(128)
)
;
SUCCESS: Processed without errors
SQL>
🚩🚩🚩Red Flag: DATES as VARCHARs
DATE$ VARCHAR2(128) -- ew, no no no
Why is this a red flag? You will wanting to query those dates as dates, and to do so you’ll need to use a function to convert them, that’s both ugly and slow(er) than if it were just stored as it should be, a DATE.
To fix this, we need to tell the LOAD command what date format to expect when streaming the data through from the file to the table.
Let’s ‘peek’ at the data
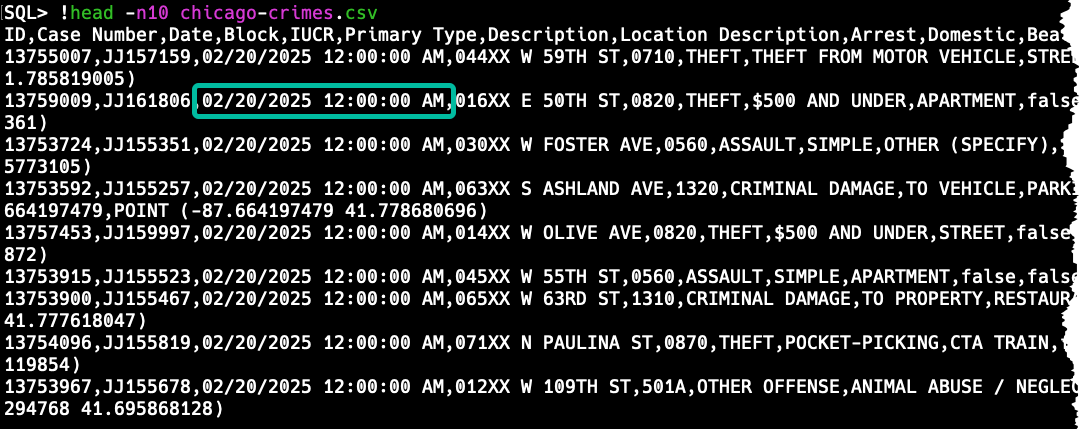
Alright, now I know how Chicago’s data portal is choosing to communicate when a crime has happened, now I need to tell SQLcl that.
show load and set load
‘show load’ will tell me what the current settings are for doing a LOAD job.
SQL> show load
batch_rows 50
batches_per_commit 10
clean_names transform
column_size rounded
commit on
date_format
errors 50
map_column_names off
method insert
timestamp_format
timestamptz_format
locale
scan_rows 100
truncate off
unknown_columns_fail on
SQL> set load date_format MM/DD/YYYY HH:MI:SS AMNow that I’ve done this, let’s try the LOAD command, again.
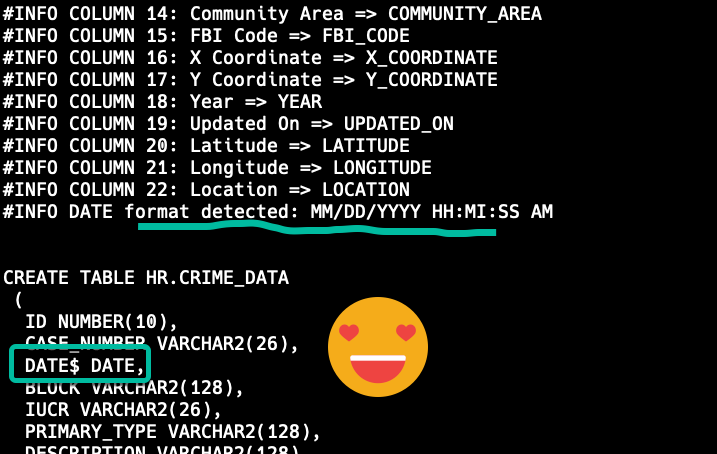
I hate that new column name, but changing column names is trivial, let’s load that sucker!
Creating/Loading the new table
On the load command, instead of using ‘show’ keyword on the end, I simply use ‘new.’
SQL> load crime_data chicago-crimes.csv new
csv
column_names on
delimiter ,
enclosures ""
double off
encoding UTF8
row_limit off
row_terminator default
skip_rows 0
skip_after_names
Create new table and load data into table HR.CRIME_DATA
batch_rows 50
batches_per_commit 10
clean_names transform
column_size rounded
commit on
date_format MM/DD/YYYY HH:MI:SS AM
errors 50
map_column_names off
method insert
timestamp_format
timestamptz_format
locale English United States
scan_rows 100
truncate off
unknown_columns_fail on
#INFO COLUMN 2: Case Number => CASE_NUMBER
#INFO COLUMN 3: Date => DATE$
#INFO COLUMN 4: Block => BLOCK
#INFO COLUMN 6: Primary Type => PRIMARY_TYPE
#INFO COLUMN 7: Description => DESCRIPTION
#INFO COLUMN 8: Location Description => LOCATION_DESCRIPTION
#INFO COLUMN 9: Arrest => ARREST
#INFO COLUMN 10: Domestic => DOMESTIC
#INFO COLUMN 11: Beat => BEAT
#INFO COLUMN 12: District => DISTRICT
#INFO COLUMN 13: Ward => WARD
#INFO COLUMN 14: Community Area => COMMUNITY_AREA
#INFO COLUMN 15: FBI Code => FBI_CODE
#INFO COLUMN 16: X Coordinate => X_COORDINATE
#INFO COLUMN 17: Y Coordinate => Y_COORDINATE
#INFO COLUMN 18: Year => YEAR
#INFO COLUMN 19: Updated On => UPDATED_ON
#INFO COLUMN 20: Latitude => LATITUDE
#INFO COLUMN 21: Longitude => LONGITUDE
#INFO COLUMN 22: Location => LOCATION
#INFO DATE format detected: MM/DD/YYYY HH:MI:SS AM
CREATE TABLE HR.CRIME_DATA
(
ID NUMBER(10),
CASE_NUMBER VARCHAR2(26),
DATE$ DATE,
BLOCK VARCHAR2(128),
IUCR VARCHAR2(26),
PRIMARY_TYPE VARCHAR2(128),
DESCRIPTION VARCHAR2(128),
LOCATION_DESCRIPTION VARCHAR2(128),
ARREST VARCHAR2(26),
DOMESTIC VARCHAR2(26),
BEAT VARCHAR2(26),
DISTRICT VARCHAR2(26),
WARD NUMBER(4),
COMMUNITY_AREA NUMBER(4),
FBI_CODE VARCHAR2(26),
X_COORDINATE NUMBER(9),
Y_COORDINATE NUMBER(9),
YEAR NUMBER(6),
UPDATED_ON DATE,
LATITUDE NUMBER(13, 9),
LONGITUDE NUMBER(13, 9),
LOCATION VARCHAR2(128)
)
;
#INFO Table created
#INFO Number of rows processed: 28,268
#INFO Number of rows in error: 0
#INFO Last row processed in final committed batch: 28,268
SUCCESS: Processed without errors
SQL> And is that the expected result? Let’s check the records loaded vs the file.
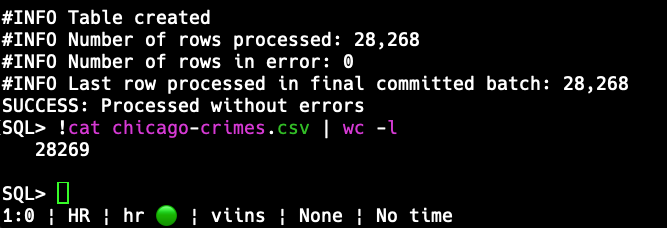
Yup, that tracks, I have an extra records, being the CSV header, which doesn’t get loaded as a row.
Let’s look at the table
But first, let’s collect the stats.
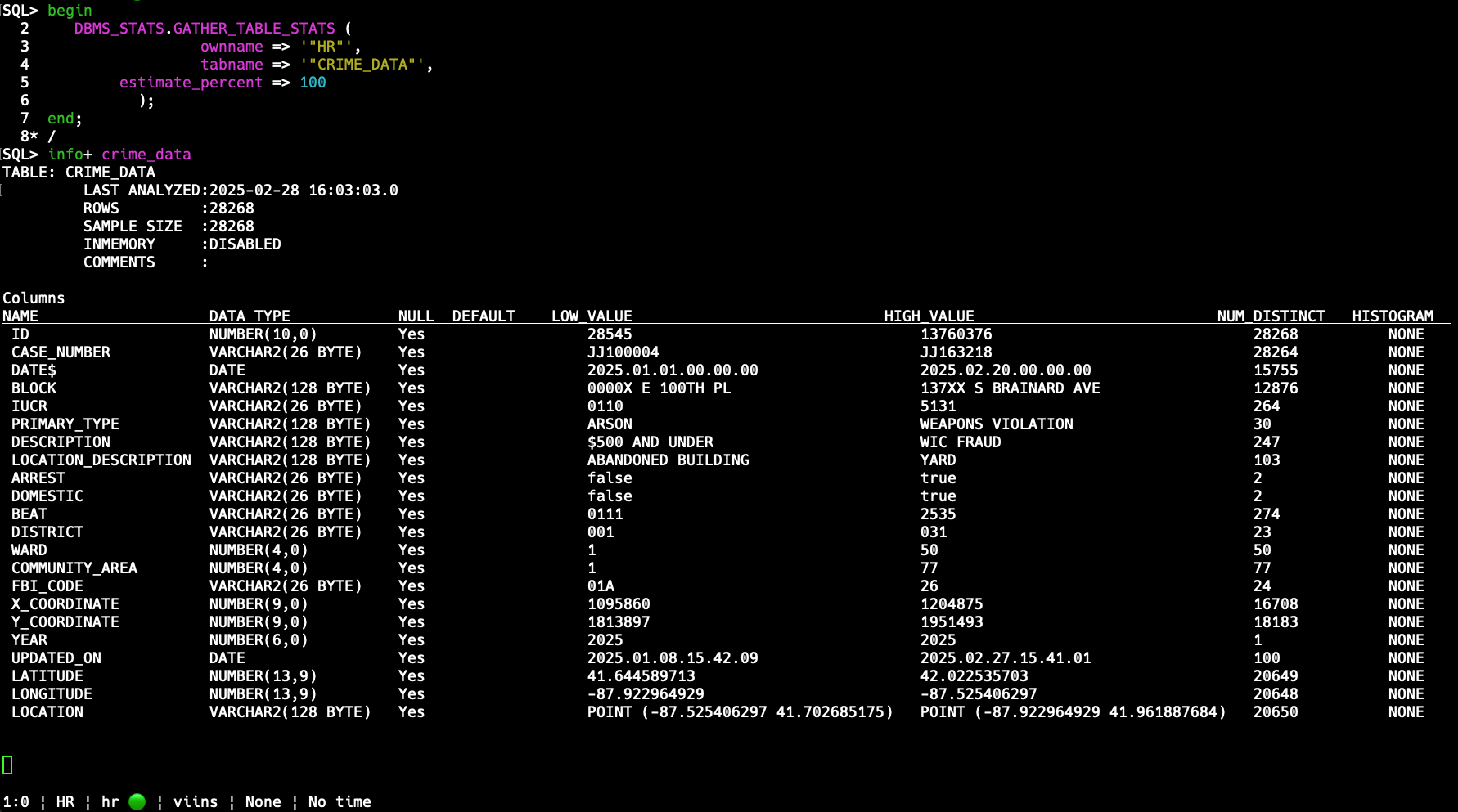
INFO+ is like DESC, but on steroids – the good kind! It shows the table definition, but with statistics thrown in.
Let’s rename that column
I can use VS Code and our SQL Developer Extension for that.
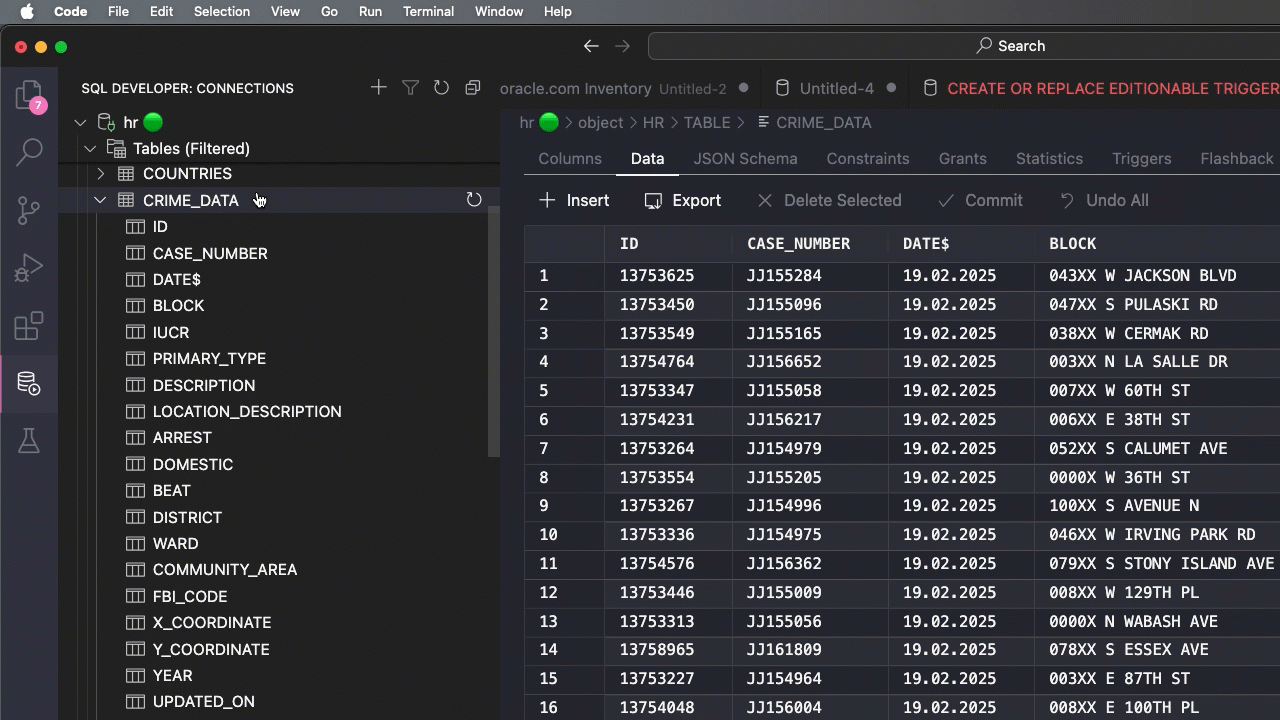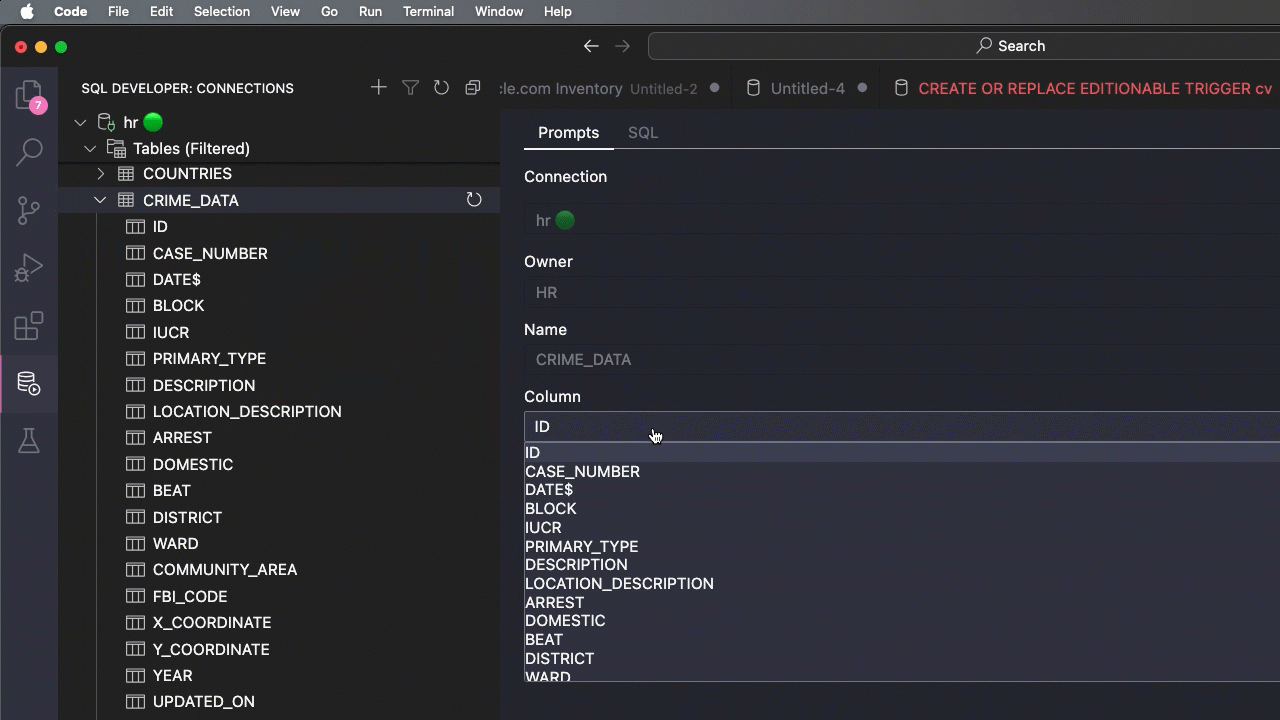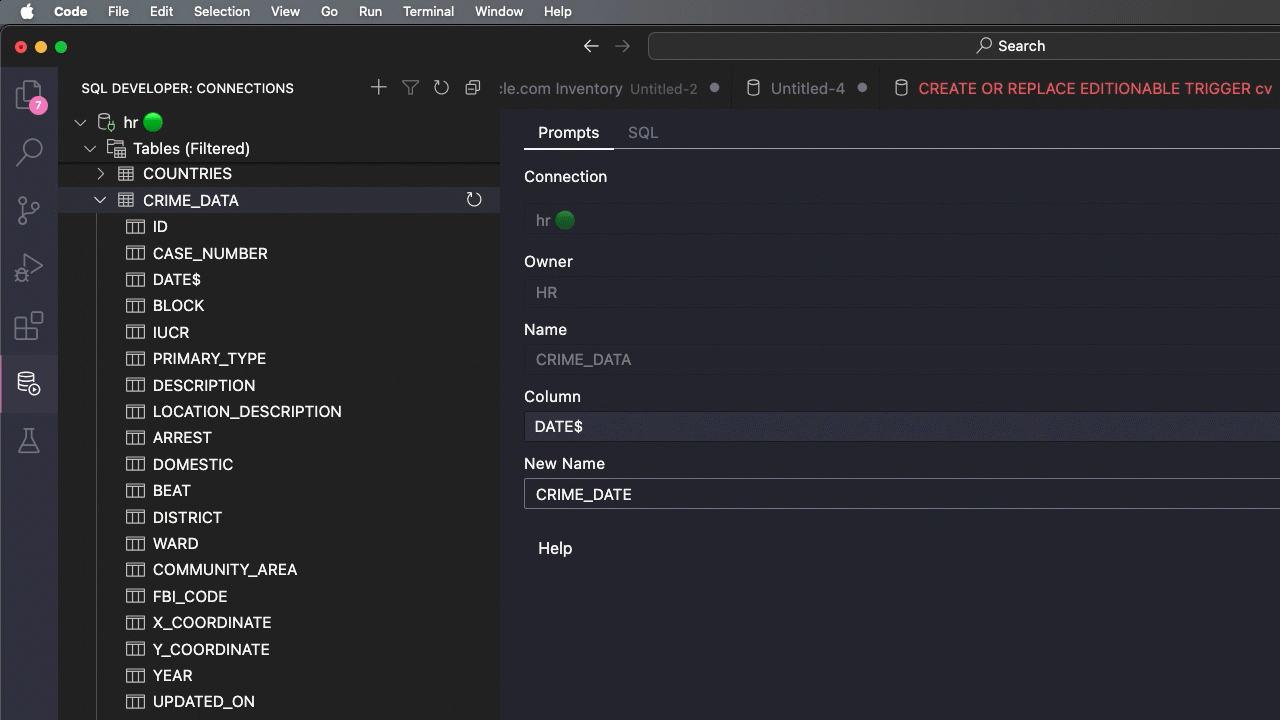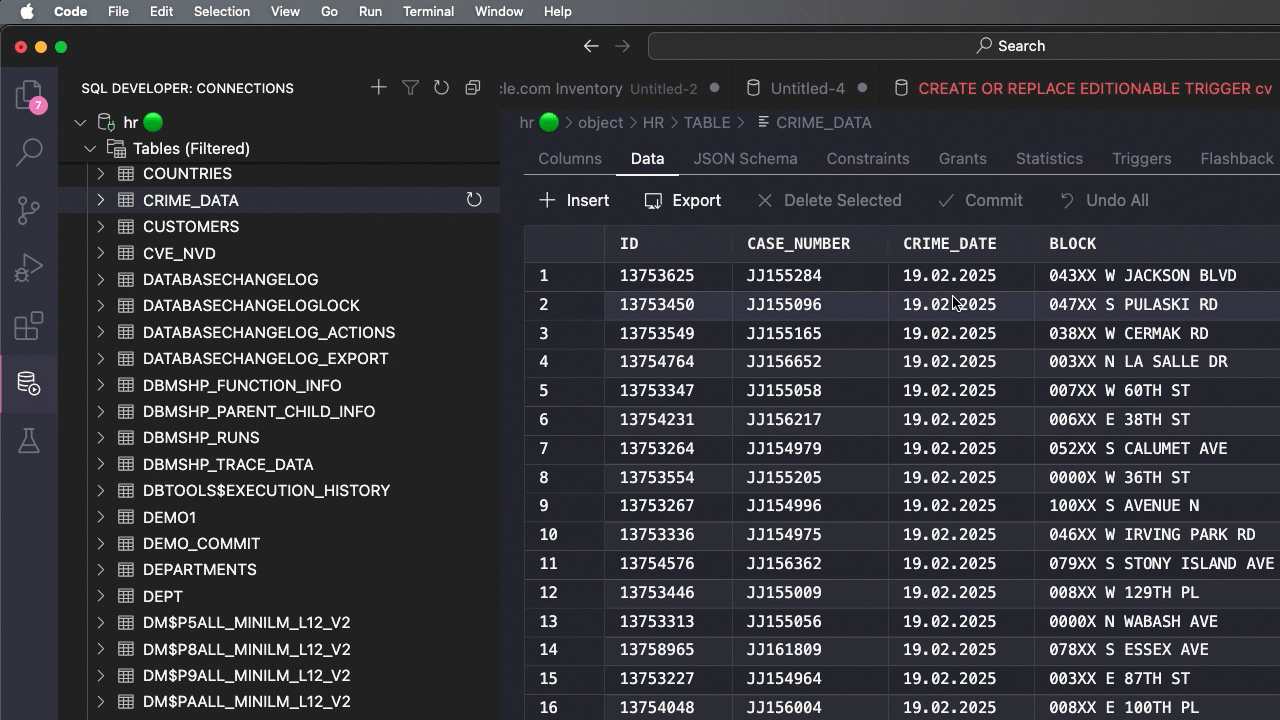
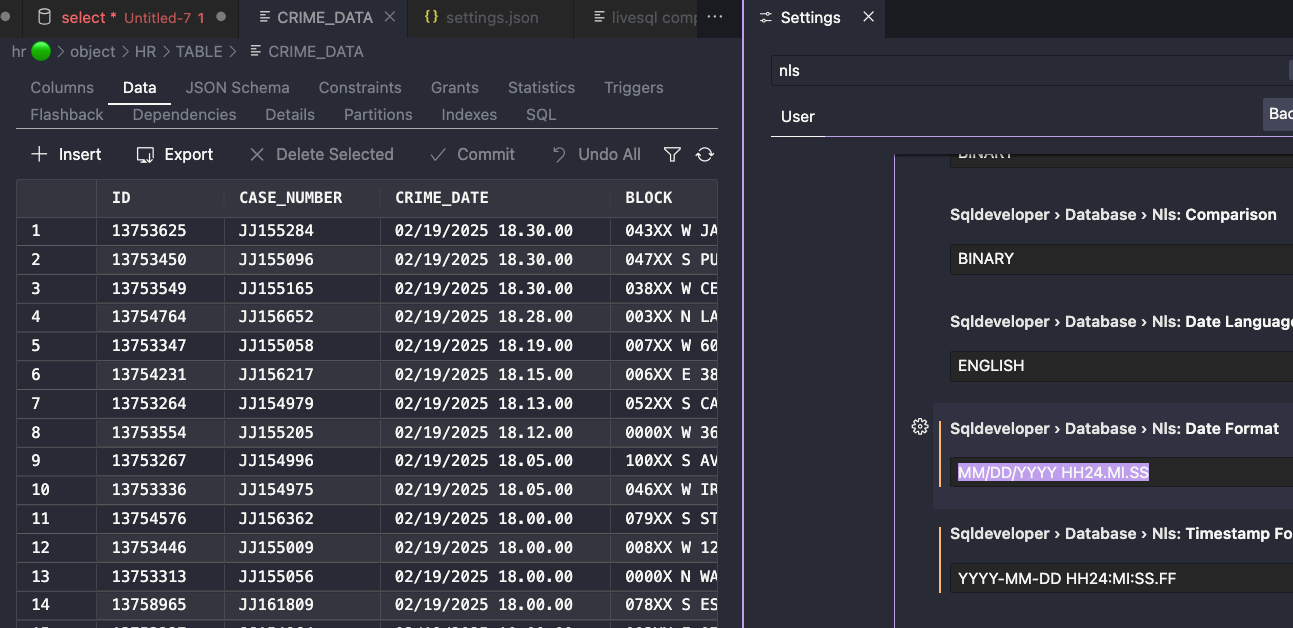
Oh, my date format is off, let’s fix that too.
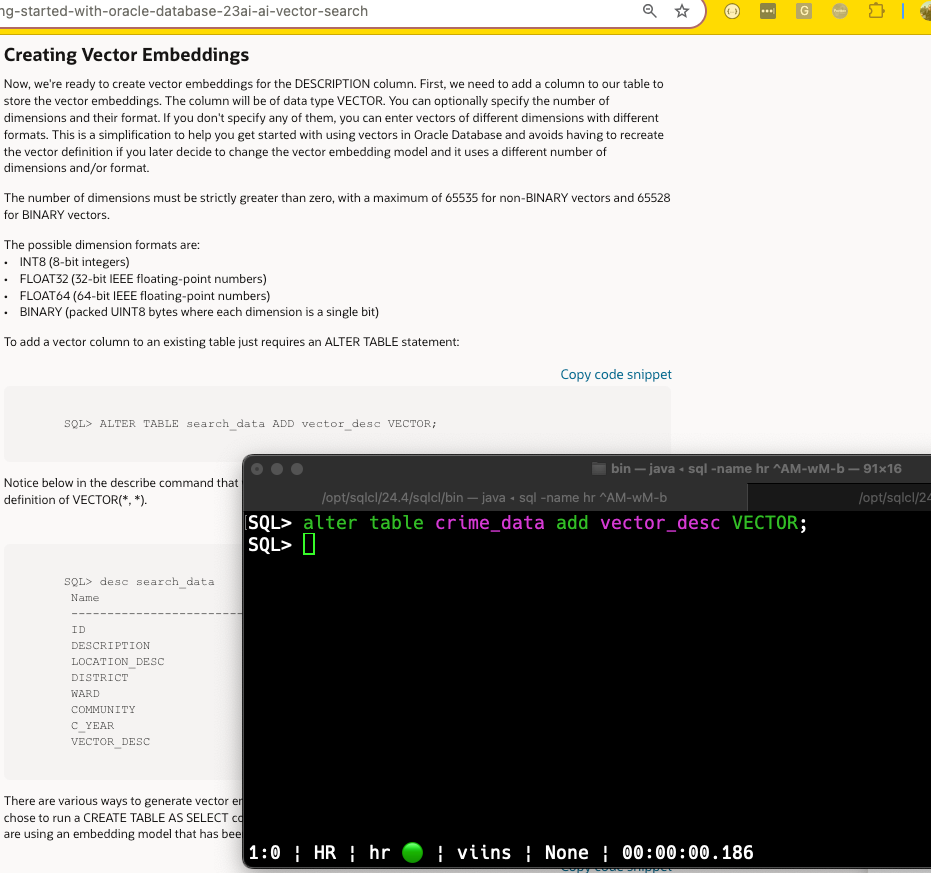
And now that I’ve got the data, I can start playing AND learning from Andy’s getting started with AI Vector Search post.
If you made it this far…
You might be interested in seeing my other posts where I talk about how to load data from CSV to your Oracle Database tables