Nearly 7,000,000 Oracle professionals use SQL Developer on a regular basis. Have a question about Oracle SQL Developer? Searched this blog and couldn’t find the answer? Ask away!
If your question is about Oracle Database, SQL, PL/SQL, etc – go Ask Tom!
Feel free to ask anything you want, but I’ll feel free to send you to Support or our Forums if it goes sideways.
Note: This page has turned out way more successful(?) than I would have ever imagined. Please keep these things in mind when asking questions.
- I am NOT support. Don’t expect me to log bugs for you, or give you official timelines on bug fixes, enhancements, or product releases.
- I AM NOT SUPPORT. Don’t open an SR with My Oracle Support AND leave a question here. Pick one and go with it, and when in doubt, go to My Oracle Support.
- I try to answer questions as quickly as possible. If you don’t get an answer, ask me for an update. I may have just forgotten or overlooked your request.
Go!
8,013 Comments
I would love a way within SQL Developer to switch connections in the script. One that used the SQL Developer stored connections with the password, since including the password in the script is a no-go. Something like
conn !my_connection_name_here
I use this constantly on Microsoft SSMS using the syntax
:connect server_name_here
Any chance we’ll see that in SQL Developer or the cl?
Thanks Jeff for clarifying that repository can be created only by a highly privileged user.
what DB privileges are needed for the user to have the ability to create the repository?
Hi Jeff
the user I am using has all elevated privileges including
Select on DBA_TAB_PRIVS
Execute on DBMS_LOCK
however, still I am getting the error.
is there any other role / priv we are missing.
thanks in advance
I am trying to use Oracle SQL developer 4.2 for UNIT testing. And would like to create repository with the same user that I am logged in. I get a message “Incorrect repository version: you must upgrade this repository to use it”
how can I update this or create a new one?
do I need DBA privileges for this purpose
You need to associate your connection with the unit testing repo, then it should prompt you to create the objects.
can you guide how to connect the unit test repo with the connection
open Unit Test panel
then on Tools Menu, Unit Test – Select Current Repository
Hi Jeff
I am missing something ….
Our Oracle DB is 11g and am using Oracle SQL Developer 4.2.
created the connection to the DB
Then View–>Unit Test
this created a repository Unit Tests
when I tried to associate this to the main DB connection, gives a message
“No repository was found on the selected connection.
would you like to create one now ?
when I click Yes, the msg is
“Required roles do not exist
You will now be prompted for connection info to grant needed permissions”
and then it prompts for sys pwd.
is it necessary that only sys has this role to create another repository?
is there any other way to create the repository.
Also I am not able to get the
UNIT TEST NAVIGATOR window
can you guide step by step as to how I can start creating repository and test cases ?
you need a highly privileged user to create the repository, yes
We have been using the modeler read all the objects in an APEX schema (tables, views, constraints, indexes, sequences, triggers) for this project and we have run across some issues:
• The table FCI_L_MAJOR table is invisible within the model. I learned of this because the FCI_ENROLLMENT table has a foreign key constraint with the FCI_L_MAJOR table that link does not appear in the model either. So I created another version of it in the model and when I tried to create the foreign there in the Referenced Table dropdown you see both tables
• When I exported the SQL from the model it’s fine except that the sequences don’t have the START WITH clause which is important since there is data already in the tables.
• When I imported the schema I tried to suppress the schema name from the model what happened is that no objects came across into the model.
hi Jeff
We are using SQL Developer version 4.1.3.20
The problem for some developers is that when they open in SQL developer file with extension ‘pkg’ – the file is open in text editor and SQL developer does not give the options to compile it
The other developers can open the same file type in pl/sql editor.
None of developers have pkg file type defined in Tool – preferences – file types.
What is the problem here and how can we resolve it to be consistent for all developers.
TIA
we have pks and pkb not pkg in the extension preferences.
What happens if they open a pkg spec or body from the DB and then save it as a pkg file?
If I do that, and then close it, and open the file, it goes into the pl/sql editor with the compile and other pl/sql specific features available.
Hi, struggling with the way SQL-DEV (SD) displays dates vs TOAD in the query results . I rely on timestamps! So I changed my SD pref to add HH:MI:SS AM to the date format in DB / NLS setting. When running a query that truncs other date fields that I only need to see the short date, SD displays DD-MON-RR 12:00:00 AM.. In TOAD, the trunced date displays as expected, just the date…
any guidance is appreciated…
They’re artificially hiding the time from you – if you ask me, they’re training you to learn a bad habit.
If the time component is important to you, then build it into your query, and don’t rely on what NLS is set to. Even if the time is midnight, it’s still there – either you want to see the time, or you don’t.
Hi Jeff, I have read several tips on making SQL Developer faster, but I have not found the problem I am experiencing as being addressed.
In short this is NOT a SQL running slowness. I am experiencing a 1-2 minute delay when I click on the export option on a SQL result set? There are additional delays in traversing the explore file structure. Once I get a file type and name selected I am fine, but getting there is becoming progressively slower.
I am running Windows 7 on a Lenovo with 4GB mem.
With SQL Developer CLOSED, try this
I went under this folder – “AppData\Roaming\SQL Developer\system4.1.5.21.78\o.sqldeveloper.12.2.0.21.78” and opened “product-preferences.xml”.
Went to the line
hash n=”URLFileChooserPaths”
list n=”DEFAULT_CONTEXT”
url protocol=”file” path=”/G:/Queries/Reference.sql”
and under list n=”DEFAULT_CONTEXT” I had LOTS of file paths. I deleted them and kept couple of them which I really need. That made ALL the difference.
Thanks! I had about 75 URLs in there that I didn’t need. It sped up some from that change. I still have about a 30 -60 second wait from when I right click export, before I see the export wizzard screen.
I’m guessing you still have a network drive or some directory in there that’s taking windows a long time to respond to our java dir/url request.
Yes, that might be it. Anyway, the response time did improve with your recommendation. Thanks!
Hi Jeff,
I have entered an Oracle support bug last year, b/c we are migrating 20+ TB of Sybase databases to Oracle using SQL Developer. We have found that single column primary keys (which is over 90% of primary keys) don’t migrate correctly.
Here is the support ticket:
SR 3-12869054401 : SQL Developer migration tool omits column name in single column primary keys
Here is the response from Oracle support:
“The workaround is to use 2 keys or more for the PK to get passed this issue. ”
What are your feelings on this? Going back and adding 2 columns to each primary key in our legacy Sybase databases just to migrate them to Oracle doesn’t sound like a solid plan.
Thanks,
Brian
That’s a crazy workaround for an obvious bug, however R&D isn’t able to reproduce that behavior. Can you send in a test case for your SR?
Thanks! They kept trying to close the ticket, but I’ll try to work with them some more and post the outcome here.
They should be contacting you soon for a test case. If you don’t hear from them by EOB tomorrow, write me back.
Yes, they have contacted me for a test case. Thanks for helping to facilitate!
Anytime. It’s easy to get lost in the machine, I’ll help for as long as I can remain somewhat sane 🙂
Hi Jeff
First, *many* thanks for your contribution – you’ve been a lifesaver more times than I’d like to admit!
Sorry if my post is a bit long, but I want to give you as complete a view as possible.
I’m trying to build a dev environment on my Ubuntu 16.10 box. I’ve set up an Oracle VM with Centos7 and installed Oracle 11.2 in it.
Since the version that comes with the DB is *way* too old, I’m trying to install sqldeveloper-3.2.20.09.87 (I need this version due to a plugin requirement).
I unzipped the file into /opt. I then ran the following and copy-paste the output here:
$ java -version
openjdk version "1.8.0_121"
OpenJDK Runtime Environment (build 1.8.0_121-b13)
OpenJDK 64-Bit Server VM (build 25.121-b13, mixed mode)
$ which java
/usr/bin/java
$ ls -la /usr/bin/java
lrwxrwxrwx. 1 root root 22 Mar 1 16:08 /usr/bin/java -> /etc/alternatives/java
$ ls -la /etc/alternatives/java
lrwxrwxrwx. 1 root root 73 Mar 1 16:08 /etc/alternatives/java -> /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.121-0.b13.el7_3.x86_64/jre/bin/java
$ ls -la /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.121-0.b13.el7_3.x86_64/jre/bin/java
-rwxr-xr-x. 1 root root 7344 Jan 20 19:37 /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.121-0.b13.el7_3.x86_64/jre/bin/java
$ /opt/sqldeveloper-3.2.20.09.87/sqldeveloper.sh
Oracle SQL Developer
Copyright (c) 1997, 2011, Oracle and/or its affiliates. All rights reserved.
Type the full pathname of a J2SE installation (or Ctrl-C to quit), the path will be stored in ~/.sqldeveloper/jdk
/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.121-0.b13.el7_3.x86_64
Error: /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.121-0.b13.el7_3.x86_64/bin/java not found
Additionally (as root):
# find / -type f -name java
/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.131-2.6.9.0.el7_3.x86_64/jre-abrt/bin/java
/usr/lib/jvm/java-1.7.0-openjdk-1.7.0.131-2.6.9.0.el7_3.x86_64/jre/bin/java
/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.121-0.b13.el7_3.x86_64/jre/bin/java
/var/lib/alternatives/java
/ora01/app/oracle/product/11.2.0/db_1/jdk/bin/java
/ora01/app/oracle/product/11.2.0/db_1/jdk/jre/bin/java
/ora01/app/oracle/product/11.2.0/client1/jdk/jre/bin/java
/ora01/app/oracle/product/11.2.0/client1/jdk/bin/java
So, what is it? Do I have an SDK for sqldev to work?
What must I do to make sqldeveloper-3.2.20.09.87 start, *without* messing with the DB (and its java) installation?
Thanks in advance for your time
Greg
Just to clarify: I’m trying to install in the VM (Centos) environment – not in host (Ubuntu).
Greg
Yes, you need a JDK.
For a version that old, Java 6 is probably ok…But we don’t support open JDK, only Oracle Java. You could probably point it to the jdk in the Oracle home bin.
Hi Jeff and many thanks for your answer.
I wasn’t aware that only Oracle Java is supported – as a matter of fact, I’ve installed sqldeveloper-3.2.20.09.87 using /usr/lib/jvm/java-8-openjdk-amd64 and it works fine – but it’s in the host (Ubuntu), not in VM (Centos).
In the VM, pointing to either db or client’s jdk (they are the same) leads to error (the same error for both):
$ /ora01/app/oracle/product/11.2.0/db_1/jdk/bin/java -version
java version "1.5.0_51"
Java(TM) 2 Runtime Environment, Standard Edition (build 1.5.0_51-b10)
Java HotSpot(TM) 64-Bit Server VM (build 1.5.0_51-b10, mixed mode)
$ /ora01/app/oracle/product/11.2.0/client1/jdk/bin/java -version
java version "1.5.0_51"
Java(TM) 2 Runtime Environment, Standard Edition (build 1.5.0_51-b10)
Java HotSpot(TM) 64-Bit Server VM (build 1.5.0_51-b10, mixed mode)
$ /opt/sqldeveloper-3.2.20.09.87/sqldeveloper.sh
Oracle SQL Developer
Copyright (c) 1997, 2011, Oracle and/or its affiliates. All rights reserved.
Type the full pathname of a J2SE installation (or Ctrl-C to quit), the path will be stored in ~/.sqldeveloper/jdk
/ora01/app/oracle/product/11.2.0/db_1/jdk
Exception in thread "main" java.lang.UnsupportedClassVersionError: Bad version number in .class file
at java.lang.ClassLoader.defineClass1(Native Method)
at java.lang.ClassLoader.defineClass(ClassLoader.java:621)
at java.security.SecureClassLoader.defineClass(SecureClassLoader.java:124)
at java.net.URLClassLoader.defineClass(URLClassLoader.java:260)
at java.net.URLClassLoader.access$100(URLClassLoader.java:56)
at java.net.URLClassLoader$1.run(URLClassLoader.java:195)
at java.security.AccessController.doPrivileged(Native Method)
at java.net.URLClassLoader.findClass(URLClassLoader.java:188)
at java.lang.ClassLoader.loadClass(ClassLoader.java:307)
at sun.misc.Launcher$AppClassLoader.loadClass(Launcher.java:268)
at java.lang.ClassLoader.loadClass(ClassLoader.java:252)
at java.lang.ClassLoader.loadClassInternal(ClassLoader.java:320)
If I install Oracle java(jdk) 6 or 8 in the VM, what must I do to make certain that the db is not affected (PATH etc)?
Thanks once more
Greg
Don’t run sqldev on the VM…Save those resources for your database.
Install sqldev on your host, and grab version 4.2 with Java 8, and just connect to the database on your VM. Then you have nothing to worry about.
Thank you very much for your time – much appreciated.
Greg
Hi Jeff
Downloaded Sqldeveloper (V4.2.0.17.089, Build 17.089.1709) and every now and then getting Connection reset message
And Code Outline, it does not shows outline for some of the packages, can see below messages in logging page
SEVERE 17410 655 oracle.dbtools.raptor.backgroundTask.RaptorTaskManager$1 null at oracle.dbtools.raptor.plsql.structure.OutlinePanel.getPopupMenu(OutlinePanel.java:385)
SEVERE 17409 200 oracle.dbtools.raptor.backgroundTask.RaptorTaskManager$1 null at oracle.dbtools.raptor.plsql.structure.OutlinePanel$2.mouseClicked(OutlinePanel.java:153)
I’ll need code samples to test with, open a thread on the forums if you can.
The table is there. The table does not exist. sqlcl-4.2.0.17.096.0933
SQL> SELECT TABLE_NAME FROM USER_TABLES WHERE TABLE_NAME = ‘DIM_FCTS_CMC_CLMD_IDCD_CD’;
TABLE_NAME
——————————
DIM_FCTS_CMC_CLMD_IDCD_CD
SQL> DESCRIBE DIM_FCTS_CMC_CLMD_IDCD_CDERROR:
——————————————————
ERROR: object DIM_FCTS_CMC_CLMD_IDCD_CD does not exist
Does info work?
What kind of table is this?
DESC on HR.EMPLOYEES works for me
SQL CL v4.2.0.17.073
Windows 7
I have a local variable for TNS_ADMIN
in SQLDev I can use the TNS alias
In SQLCl I get an error where SQLCl is looking for jdbc connect string
If i use the jdbs connect string with /Service_name then I can connect.
What am I missing in making the tnsnames alias to work?
Show me what you’re doing.
And when you’re in SQLcl, run
SHOW TNS
It will tell you what tnsnames files we find and what entries are available.
HI Jeff,
I am using SQL Developer Data Modeler 4.15 and I am using the compare feature of the modeler but I am getting some odd results when I read the data dictionary from an APEX 5.0 instance. What I am getting is additional tables that are not in the schema, any idea why this is happening?
I’d have to see what you’re talking about to even hazard a guess.
What tables are being shown that aren’t actually there?
The list of tables are below and they are the same the two tables that are not in either model are agency and AGENCY_CONTACT . These two tables are not there.
FCI_ADDRESS
FCI_ENROLLMENT
FCI_HOUSING
FCI_INIT_ENROLL_INFO
FCI_INTERNSHIPS
FCI_L_AGENCY
FCI_L_CODE
FCI_L_COLLEGE_DEPT
FCI_L_CONTACT
FCI_L_COUNSELORS
FCI_L_INTERNSHIP_TYPE
FCI_L_MAJOR
FCI_L_MEETING_TYPE
FCI_L_PROGRAM
FCI_MEETING
FCI_STG_ROSTER
FCI_STUDENT
FCI_STUD_CONTACT
I don’t have those tables in my APEX 5.0 install.
The tables I am talking about are not APEX tables but user created tables that I am comparing to the model. I selected the application tables I created in the in my workspace for the FCI application and compared it the FCI model in the modeler version 4.15. What I got is two tables that are not in the model or in the schema I was comparing. That is AGENCY and AGENCY_CONTACT which are in neither. Why?
I don’t have your tables, so I can’t test.
When using the Sqlcl “ddl” command to retrieve the source for a proc or package, empty lines within the source are being dumped. Is there some-or-another option that controls this?
Blank lines?
There are options for how the DDL is shaped.
A proc that should have empty lines..
SQL> create or replace procedure
2 uselessproc(
3
4 — What a useless argument
5 LevelOfUseless varchar2
6 )
7 as
8 begin
9
10 /*
11 This proc has plenty of open lines in it
12
13 Open lines are important to the readability of code
14 */
15
16 dbms_output.put_line(‘I do nothing useful ‘);
17
18
19 end;
20 /
.. is returning without them..
SQL> ddl uselessproc;
CREATE OR REPLACE EDITIONABLE PROCEDURE “SCOTTM”.”USELESSPROC”
(
— What a useless argument
LevelOfUseless varchar2
)
as
begin
/*
This proc has plenty of open lines in it
Open lines are important to the readability of code
*/
dbms_output.put_line(‘I do nothing useful ‘);
end;
/
If you have setup the formater to your liking, you can do:
SQL> ddl uselessproc;
SQL> format buffer
Not prefect but better the eating blank lines.
Hi Jeff
Thanks for your site. it is really useful.
In Oracle SQL Developer, how can I increase the number of entries shown in the
File -> Reopen menu?
Thanks in advance
Regards
Vadi
Bengaluru, India
Hi Jeff,
we’re attempting to integrate Oracle SQL Developer unit testing with Bamboo, and in doing this we have to first setup the DB connections. The Bamboo script can run on multiple agents, so it’s best to create a connection first (passwords can be stored securely in Bamboo), then import and run the tests, then remove the connection. So here’s what we tried for creating the connection (Windows PowerShell):
.\sdcli migration -actions=mkconn -connDetails=”MyConnection:oracle:TEST_USER/password@(DESCRIPTION=(ADDRESS=(PROTOCOL=TCP)(HOST=DBSERVER.SOMECOMPANY.COM)(PORT=1521))(CONNECT_DATA=(SERVICE_NAME=DB123.SOMECOMPANY.COM)))”
…or with TNS:
.\sdcli migration -actions=mkconn -connDetails=”MyConnection:oracle:TEST_USER/[email protected]”
In both cases we get the following error message:
Error:Problem creating connection:Test failed: IO Error: Connect identifier was empty.
Do you have a clue what we’re doing wrong? Thanks a lot for any help.
Jan
Jeff,
I am trying to improve my workflow by reducing the number of times I export data from SQL Developer into Excel. I often find myself copying data from SQL Developer to Excel in order to quickly locate a column in a large set of data.
When working in SQL Developer’s Query Result window, CTRL+F only evaluates the data returned from my query, excluding column headers.
Is there a way to quickly search in the Query Result window for a column name? I do not see anything listed in the Shortcut Keys section of Preferences.
Connor
Column name, no.
Have you tried the single record view? It can make looking at wider data a bit easier on the eyes.
Thanks Jeff. Single Record View does help a tad. It would be great to have “Column Names” as selection in the Options section of the Find window.
You’re not the first to ask, I’ll see what we can do.
Just following up on the improvement of searching in the query results window. My workflow is constantly disrupted when needing to quickly find data in a large set.
Nothing yet. It’s not scheduled for a release, but that could change. If you want formal updates for an enhancement request, please submit a Service Request to My Oracle Support.
When exporting ODDM (4.1.5) designs to reporting schema, it seems that only the logical diagram can be save as pdf while any subview diagrams can not. I checked DMRS_DIAGRAMS.DIAGRAM_PDF column and records for subview diagrams are empty. Where is the problem or this is the expected feature for this version. The previous version 3.1.2 can creates pdf diagrams for logical or subviews diagrams when export to reporting schema.
Sounds like a bug.
Hi Jeff,
I came across a response from you to my exact issue at http://theoracleemt.blogspot.com. I have posted your response below. I am using version 4.1.5.21 and I normally return queries with several hundred thousand rows. These queries often take a while so before I export to .xlsx I bring all of the data into the grid as to not run the query again. I normally have no problem doing this and then exporting for several hundred thousand rows and roughly 20-30 columns. However lately, Oracle has been hanging, freezing, crashing and I get the memory error. I’m confused as to why this is happening all of a sudden when I am normally able to do it without an issue. Your response is from 2015 so I am wondering if anything has changed since then or do I just need to run the query 2x to export it.
thank you
thatJeffSmithOctober 6, 2015 at 10:23 AM
So from what I can tell, this refers to the scenario where the user attempts to fetch ALL the data from the database to the grid before doing the export.
There’s only one reason I can think of for doing this – the query takes a very long time to run, and you don’t want to run it again to do the export.
If the amount of data is high enough to overwhelm the JVM as it’s put into the Grid, then it’s going to ‘hurt.’
If you’re doing exports, you should never run into memory issues…UNLESS…you’re exporting to Excel and you’re using the older XLS format instead of the newer XLSX format.
Our library for creating XLS files doesn’t support letting go of the data as it’s written to the spreadsheet, so after 100,000 rows or so the JVM is exhausted and the app will ‘hang’ – or in newer versions it will complain. So almost always:
+ don’t fetch all the data down to the client first
+ use XLSX not XLS
Are you writing to XLSX?
Unless the query takes 10 minutes to run, I wouldn’t fetch the data down to the sqldev grid first – asking it to keep 100k+ rows of 20-30 columns is excessive.
And even if the query takes 10 minutes to run, I’d write a script to spool the data out to a CSV file and run that instead.
I am writing to xlsx. The individual query takes anywhere from 20-30 minutes. I just attempted to export directly instead of filling the grid first and it was running for over an hour so I killed it. I have attempted to spool the data previously and could never get it to work properly. Like I mentioned I normally fill the grid without an issue with a lot of data, it is only recently that it has been a problem.
So, I’ll assume the query can’t be tuned.
Have you tried increasing the JVM max heap size?
>>I have attempted to spool the data previously and could never get it to work properly
What did you try?
I would use SQLcl, it’s much lighter weight and shouldn’t have any issue handling that amount of data.
The Query is a bit of a beast but I have tuned it as much as I think is possible. My DBA’s do not allow the creation of temporary tables so it involves a lot of sub queries.
I was reading about the JVM max heap size but I must admit that is way over my head and I’d be fearful I would break something. Maybe I will have to find someone to assist me with that.
The spool process appears to be restricted by my DBA’s as well.
SQLcl is not something I have seen before. I was looking at it on the Oracle site and the key features didn’t seem to be relevant, so not sure what I would use that for.
It looks like the heap size may be where I need to go, so I will try and hunt down some assistance with that.
thank you for your assistance as always!
SQLcl is a better SQL*Plus. Not a GUI. Just a command line interface. So it requires less resources, runs faster, but not as click-button-y as SQL Developer.
To add memory to SQLDev, just find your product.conf and edit it such that you have this near the bottom
AddVMOption -Xmx2048m
That’ll let SQLDev take 2GB of RAM when its running.
I talk about this in detail here.
Hi Jeff,
in a sql devloper report i have a bind parameter of the date datatype. i wonder if there is a chance to set the actual date as default vaule (sysdate)?
Hi Jeff,
I am trying to pick up changes made between models or a model and a database for a materialized view. I want to do this to get the DDL for the mat view – ie the change that is going to be applied to a previous model. When I get to the Pending Changes screen the mat view is not marked with the yellow caution triangle icon as other changes are. So, it appears to not recognize the change. But, if I drill down into the object I know changed until I see the properties in the bottom half of the Pending Changes screen and look at the query by double clicking the elipses it shows me the change. Clicking the generate DDL button does not put the query in the DDL. Is there a setting somewhere that will allow the query changes to be picked up?
Hi Jeff,
I’m having a weird issue with completion insight on sql developer 4.1.5
As i’m typing my table aliases and the period that follows, the completion pops up no problem. Same when i type the first letter of the table/view/whatever i’m looking for. However, as soon as I type any more letters, autocomplete goes away and will not return unless i completely erase what I’ve typed and start over. It also will not appear with ctl+space.
Am I overlooking something silly?
Thanks
No, that sounds like a bug.
So if you
that is correct. i would then have to delete what i’ve typed up until the popup would normally appear (so until the period or the first letter).
This scenario works for me
Hi Jeff,
Does SQLcl have some sort of buffer that holds the results of queries? It seems that way given the weird results I’m getting . If so is there some way to clear it?
In order to demonstrate the different time datatypes in Oracle for some managers, I created a table having a column of datatype TIMESTAMP WITH LOCAL TIME ZONE and inserted some rows using the localtimestamp function. Doing a query on the table without changing the session timezone gives the expected results. However, in the same session, changing the session time zone then repeating the query gives the same results as the first query!!! If I create a new session, change the session time zone and query again, this time I get the expected results.
In short, the first query on the table returns the expected results given the session time zone but subsequent queries always return the same result regardless of the current session time zone.
I’ve tried this experiment using SQLplus and a SQL Worksheet in SQL Developer – both of these return the proper result for the current session time zone.
Am I missing something?
Thanks.
Norm
it might be the nls timestamp TZ format…if you include that in your queries, is the data displayed as expected?
Unless I’m mistaken, NLS_TIMESTAMP_TZ_FORMAT doesn’t apply here – the issue I’m seeing is with the TIMESTAMP WITH LOCAL TIME ZONE datatype – that NLS format only applies to TIMESTAMP WITH TIME ZONE.
Just for grins and giggles I tried changing both formats (with and without the TZ) – no difference. Remember, I’m only seeing this behavior in SQLcl, not with any other client I’ve tried.
we don’t ‘listen’ for when date/timestamp formats change in the session – we catch them if you run an ALTER SESSION for example, but if you’re changing it via a script or stored proc, the client won’t know about it and continue to display the time/dates in the old format
i think to help you i need specific examples of what you’re talking about with a test-able scenario
Here is the results using SQLplus (instantclient 12.1 on Windows 7):
SQL> desc date_table
Name Null? Type
—————————————– ——– —————————-
TIME_STAMP_TZ TIMESTAMP(6) WITH TIME ZONE
TIME_STAMP_LTZ TIMESTAMP(6) WITH LOCAL TIME
ZONE
SQL> select sessiontimezone from dual;
SESSIONTIMEZONE
—————————————————————————
-04:00
SQL> select time_stamp_ltz from date_table;
TIME_STAMP_LTZ
—————————————————————————
17-MAR-17 05.42.30.596926 PM
17-MAR-17 05.42.55.639511 PM
SQL> alter session set time_zone=’-6:00′;
Session altered.
SQL> select time_stamp_ltz from date_table;
TIME_STAMP_LTZ
—————————————————————————
17-MAR-17 03.42.30.596926 PM
17-MAR-17 03.42.55.639511 PM
SQL>
Note how the returned timestamp values are now 2 hours earlier due to the change in the session time zone. This is what I expected.
Now using SQLcl (latest version – again on Windows 7)
VIENS @ patd >select sessiontimezone from dual;
SESSIONTIMEZONE
America/New_York
VIENS @ patd >select time_stamp_ltz from date_table;
TIME_STAMP_LTZ
17-MAR-17 05.42.30.596926000 PM
17-MAR-17 05.42.55.639511000 PM
VIENS @ patd >alter session set time_zone=’-6:00′;
Session altered.
VIENS @ patd >select time_stamp_ltz from date_table;
TIME_STAMP_LTZ
17-MAR-17 05.42.30.596926000 PM
17-MAR-17 05.42.55.639511000 PM
VIENS @ patd >disc
Disconnected from Oracle Database 12c Enterprise Edition Release 12.1.0.2.0 – 64bit Production
With the Partitioning, OLAP, Advanced Analytics and Real Application Testing options
@ >connect viens@patd
Password? (**********?) *********
Connected.
login.sql found in the CWD. DB access is restricted for login.sql.
Adjust the SQL_PATH to include the path to enable full functionality.
VIENS @ patd >alter session set time_zone=’-6:00′;
Session altered.
VIENS @ patd >select time_stamp_ltz from date_table;
TIME_STAMP_LTZ
17-MAR-17 03.42.30.596926000 PM
17-MAR-17 03.42.55.639511000 PM
VIENS @ patd >
Note the sequence of events:
Connect to the database.
Query the table – get the expected results for the current session time zone.
Change the session time zone.
Repeat the query – note the results are the same as the first query when they should be 2 hours earlier.
Disconnect from the session and log in again.
Change the session time zone
Repeat the query – this time the results are 2 hours earlier as expected.
also, we don’t cache data
I’ve tried a number of experiments over the last couple of days (including accessing the test table via a database link) that has me convinced that this is a bug in SQLcl (which BTW also exists in a previous version – I tried). Given this I guess I need to create an SR with support.
Thanks for listening.
Norm
It’s not ‘us’ per se, it’s another team – from what I can tell, the JDBC driver doesn’t support that.
Have you tried using a thick client connection? I’ll test it later this morning.
If it really is JDBC, this is really disturbing!! This means that JDBC doesn’t support a datatype that has existed since (I believe) Oracle 9i!! I wonder what else isn’t working right.
I believe I’m using a thick client:
VIENS @ patd >show jdbc
— Database Info —
Database Product Name: Oracle
Database Product Version: Oracle Database 12c Enterprise Edition Release 12.1.0.2.0 – 64bit Production
With the Partitioning, OLAP, Advanced Analytics and Real Application Testing options
Database Major Version: 12
Database Minor Version: 1
— Driver Info —
Driver Name: Oracle JDBC driver
Driver Version: 12.1.0.2.0
Driver Major Version: 12
Driver Minor Version: 1
Driver URL: jdbc:oracle:oci8:@(DESCRIPTION = (ADDRESS_LIST = (ADDRESS = (PROTOCOL = TCP)(HOST = pimsdb2.ext.ray.com)(PORT =
1521)) ) (CONNECT_DATA = (SERVICE_NAME = patd.pimsdb2.ext.ray.com) ) )
Driver Location:
resource: oracle/jdbc/OracleDriver.class
jar: C:/Users/94884/Documents/instantclient_12_1/ojdbc7.jar
JarSize: 3698892
JarDate: Fri Aug 29 06:14:11 EDT 2014
resourceSize: 2285
resourceDate: Thu Aug 28 19:14:38 EDT 2014
I did try this testing using a SQL Developer SQL Worksheet using both a thin and thick client connection – this WORKS in both cases. This really has me puzzled since from what I read in your blog SQL Developer and SQLcl use the same engine – why would one work correctly but the other not?
Norm
I didn’t research it deep enough to see if JDBC driver supports it or not – just found that link I shared.
Depending on version of SQLcl and SQL Developer, you could be using a different JDBC driver.
I would open a SR with MOS.
Oh – another thing – I see the same problem running SQLcl on Linux (RHEL6) so it’s not a Windows specific issue.
Norm
Not sure it’s worth the effort to pursue this issue with support at this time (don’t get be started about the royal pain is has become to create tickets on MOS – I and my coworkers only create tickets when in dire need of support). Guess I’ll just stop using this tool since I don’t trust it and will advise my coworkers not to use this tool.
I have the answer.
It’s a SQLcl bug. We’re not catching that the timezone has been updated. I’m looking for a workaround for you now until we can patch SQLcl for you. I know if you change the TZ on your machine it will reflect that for your data…but I’m looking for a way to pass the TZ to the JVM at start-up time.
Hi Jeff,
I’d like to know what in background process when connection to oracle database with Kerberos authentication check box checked. What sqlnet parameters sqldeveloper use it…? No Oracle client involved setup. How it created TGT? It is looks to me it does not do anything in client, because I didn’t specify any krb5 configuration on client machine. database on 12.1 on windows 2012; running sqldevloper on windows 7, 2008r2, 2012. all successful connection. Tried use sqlnet trace, no details. I really need to know, I need the same way in my applications.
Thanks Marina
I’m not a kerberos guy…but if you didn’t provide any thin details, then it must be coming from sqlnet.ora – you don’t have anything on tools > database > advanced page configured?
Hi Jeff,
Thanks for quick response.
tools > database > advanced — no values configured or sometimes I use tnsnames directory. Both ways it is working fine.
Hi Sir,
We are planning to use SQL Developer unit test utility for testing PL/SQL programs. We are able to test successfully procedure contains data type char,number and date with dynamically value passing. But I am not able to find a solution testing dynamically with PL/SQL record type input as well as passed. We are successful in doing the test with static values. Only problem with Dynamic Value Query.
Can you please help me how to do this?
Regards
G. Srinivasa Rao
Please post your scenario on the forums.
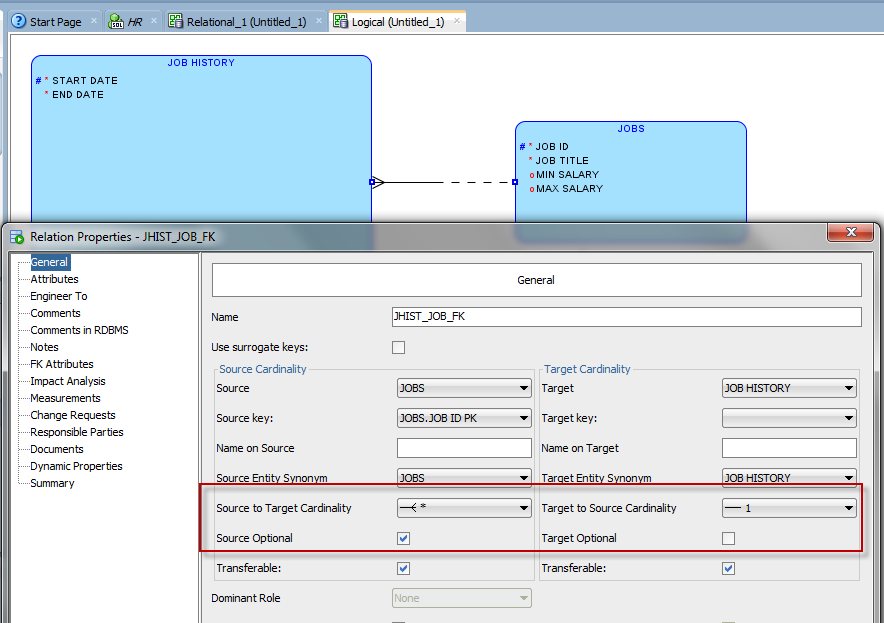
Hi Jeff,
I am struggling to find a way to change the cardinality in the model. By default I saw that is set as one to many and I want to change in 1 to 1.
I found only a solution do add in the comment cardinality=1..1 but for me it doesn’t work. Version 4.1.5, build 907
Thanks a lot,
Vlad
you define that in the logical design